Optimizing Ruby's JSON, Part 3
In the previous post, I covered how I reimplemented JSON::Generator::State#configure
in Ruby and some other changes. Unfortunately, it didn’t go as well as I initially thought.
Mistakes Were Made
The default gems that ship with Ruby are automatically copied inside ruby/ruby’s repo.
In short, there’s a bot aptly named matzbot, that replicates all the commits from the various ruby/* gems,
inside ruby/ruby, and that’s what it did with my State#configure patch.
The reason is that Ruby runs on many different platforms and its CI tests many different compilers, in different versions, and also test builds with various compilation flags enabled to hopefully catch some subtle bugs, these gems will ultimately ship as part of Ruby, so they might as well, be tested together.
Depending on which files the commit touches, it can trigger up to 150 CI tasks just on GitHub:
And that’s only the beginning, after such a commit is merged, there are other secondary CIs maintained by core contributors which will test Ruby on various OS and platforms that are hard to integrate into GitHub actions, such as Solaris and some CPU architectures I barely know the existence of.
This is centralized in a channel inside Ruby committers’ Slack: #alert-emoji.
On October 17th, Mame pinged me because that State#configure commit started making builds fail,
with this crash report:
Assertion Failed: ../src/vm_core.h:1394:VM_ENV_FLAGS:FIXNUM_P(flags)
ruby 3.4.0dev (2024-10-17T11:35:33Z master 0e2ac46584) +PRISM [i686-linux-gnu]
-- Control frame information -----------------------------------------------
Assertion Failed: ../src/vm_core.h:1394:VM_ENV_FLAGS:FIXNUM_P(flags)
ruby 3.4.0dev (2024-10-17T11:35:33Z master 0e2ac46584) +PRISM [i686-linux-gnu]
Crashed while printing bug report
running file: /home/runner/work/ruby/ruby/src/test/json/json_common_interface_test.rb
A test worker crashed. It might be an interpreter bug or
a bug in test/unit/parallel.rb. Try again without the -j
option.
This is the worst for me. Normally when Ruby runs into a SEGV or some other bug, before it exits, it collects lots of debug information including the native C stacktrace, and print a useful report that helps a lot in the debugging process.
But sometimes, the process is corrupted enough, that the crash reporter itself crashes while trying to collect that data, and that’s what happened here.
Yet, we still have a few information. Since we failed an assertion, we do know which condition was wrong:
static inline unsigned long
VM_ENV_FLAGS(const VALUE *ep, long flag)
{
VALUE flags = ep[VM_ENV_DATA_INDEX_FLAGS];
VM_ASSERT(FIXNUM_P(flags)); // CRASHED HERE.
return flags & flag;
}And we also do know that the crash was triggered by a test inside test/json/json_common_interface_test.rb, but not which one exactly.
Unfortunately, for some reason, I’m still not quite clear on why the crash would only happen on i686, aka 32-bit Intel, and all I have is an arm64 machine (I really should do something about that).
In some cases, you can use emulation layers, but it’s terribly slow, so I was looking at hours of compilation, and generally when emulating another
architecture you can’t use debuggers like gdb or lldb so it’s not that helpful.
So that’s where I called a favor from my colleague Peter Zhu, who owns an x86_64 machine, to ask him if he could get me a proper backtrace or something, and generally give me some more information about what was going on.
But Peter being Peter, he directly opened a pull request on ruby/json with the fix.
Turns out, I didn’t introduce the bug, it had been present in the State#max_nesting= since October 2009, 15 years!
My change caused it to be covered by tests, while before it wasn’t.
But you might wonder what the bug is exactly, so let me explain.
Boxing Day
In the Ruby VM, object references are held in the VALUE type, which in short is a pointer type. Meaning on 64-bit hardware it’s a 64-bit integer,
and on 32-bit hardware, it’s a 32-bit integer.
This is so that for objects that are allocated on the heap, their reference is simply a pointer to their location, and there’s no lookup or transformation needed to access that reference, you simply use it like a normal C pointer. This might seem obvious, but some other VMs don’t do it this way, it’s a tradeoff.
But not all VALUE references are an actual pointer to an active memory region on the heap, some of them are what is called “immediates”.
This is a technique often referred to as “pointer tagging”, that exploits the fact that pointers are guaranteed to be aligned on 8 bytes, in other words all the pointers you’ll
get from malloc and such will always be divisible by 8, so that (pointer % 8) == 0, always.
In binary form, that means the last 3 bits of a pointer are always 0, and Ruby would never leave 3 good bits to go to waste.
For objects that are fully immutable, like Integer, you don’t need them to be stored in allocated memory, you can simply pack them in
the pointer instead, and use these 3 bits as “tag”, to inform Ruby that it’s not a real memory pointer, but an immediate value that needs to be
massaged first to be used.
The way these are used is defined in the ruby_special_consts enum in special_const.h
and can vary based on which architecture Ruby is compiled for, typically 32-bit and 64-bit Rubies are quite different.
Here I’ll just focus on how Integer is tagged. On both 32 and 64 bits, if the least significant bit is set, then we’re dealing with an immediate integer.
So to know if a reference is an immediate integer, you just have to check that bit:
RUBY_FIXNUM_FLAG = 0x01
static inline bool
RB_FIXNUM_P(VALUE obj)
{
return obj & RUBY_FIXNUM_FLAG;
}The _P prefix is the convention used by Ruby to encode question mark ? into valid C function names, as for fixnum, that’s how integers small
enough to be immediates were called in the past. Before Ruby 2.4, you had two Integer classes, Fixnum and Bignum. The two were merged and now as a Ruby user you can only
observe a single Integer class, but internally in the virtual machine, they’re still very much distinct.
Based on this to convert a C integer into a Ruby fixnum you use some simple bitwise transformations:
def int_to_fixnum(int)
(int << 1) + 1
end
def fixnum_to_int(fixnum)
fixnum >> 1
end
p(5.times.map { |i| int_to_fixnum(i) }) # => [1, 3, 5, 7, 9]This sort of conversion is often referred to as “boxing” and “unboxing”, the idea being to take a native integer type, and put it in a “box” so that it fits the same generic pattern than all other object references. And then when you need to use it you have to “unbox” it back to the native type.
In the Ruby C API, these types of functions are provided as NUM2<ctype> and <ctype>2NUM or FIX2<ctype> and <ctype>2FIX, for instance,
to convert a FIXNUM into a native C long, you use FIX2LONG.
Going back to our crash, what Ruby was complaining about, is that it was expecting to read a FIXNUM on the stack,
but somehow, the VALUE it read wasn’t a FIXNUM, as its least significant bit wasn’t set.
static VALUE cState_max_nesting_set(VALUE self, VALUE depth)
{
GET_STATE(self);
Check_Type(depth, T_FIXNUM);
return state->max_nesting = NUM2LONG(depth);
}With what I explained above, you might be able to spot that State#max_nesting= is supposed to return a Fixnum, but actually returns the native C long integer,
and thanks to C’s weak typing, none of the many compilers Ruby is tested against ever complained about it.
You might also have deduced that this crash would only happen if depth happens to be an even number.
But also the crash was only happening on debug builds of Ruby, because that function is a setter, so unless you do something weird, the return value is just dropped on the floor.
But you can easily reproduce it on older versions of the JSON gem:
>> JSON::VERSION
=> "2.5.1"
>> JSON::State.new.send(:max_nesting=, 5)
=> 2
>> JSON::State.new.send(:max_nesting=, 4)
/opt/rubies/3.0.7/lib/ruby/3.0.0/pp.rb:582: [BUG] Segmentation fault at 0x0000000000000014
ruby 3.0.7p220 (2024-04-23 revision 724a071175) [arm64-darwin23]
....But this post is named “Optimizing Ruby’s JSON”, we’re not here to talk about bugs, so let’s move on.
Path Splitting
After the previous optimizations I mentioned in parts 1 and 2, I still wasn’t satisfied with the JSON.dump performance.
So I went back to profile the twitter.json macro benchmark:
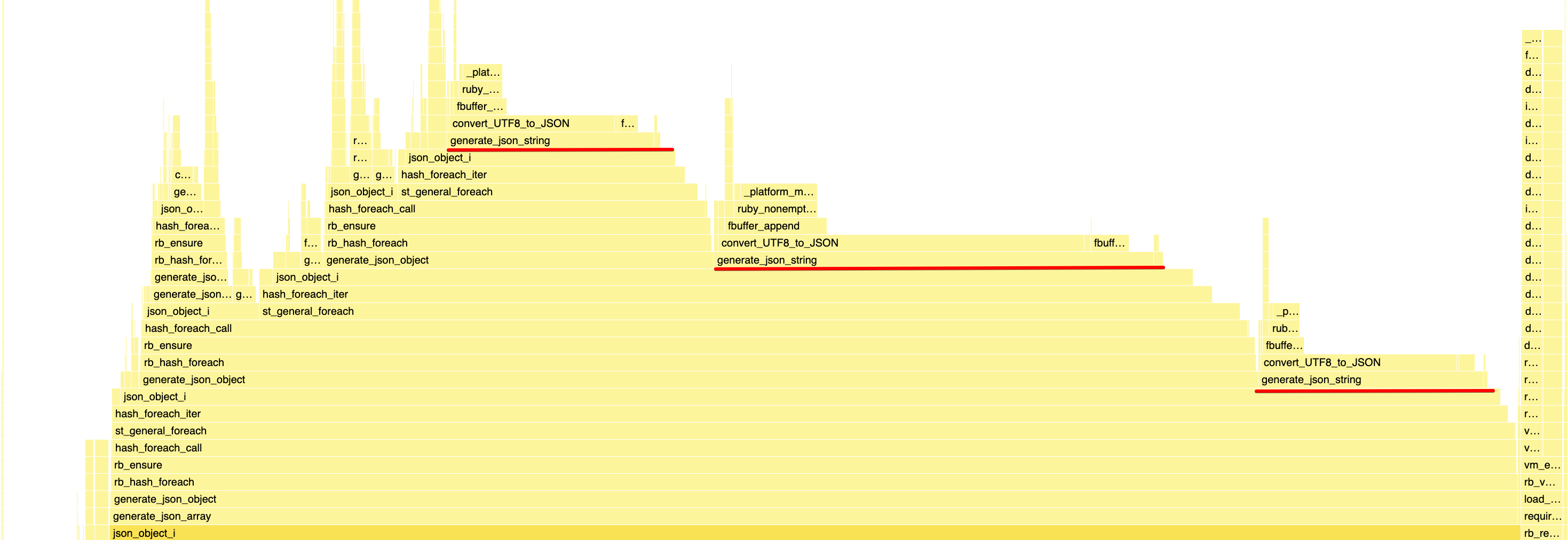
As you can see, we’re spending 55% (13% + 28% + 14%) of our time in generate_json_string, and most of that is spent in convert_UTF8_to_JSON
which is essentially our escape function.
This makes sense, of all the JSON types, it’s one of the most common and requires some costly scanning and escaping.
Having such an obvious hotspot is pleasant in a way, as it gives you a very specific area to focus on.
Looking more specifically at the heatmap of convert_UTF8_to_JSON, we can see that Mame’s precondition check
helps, but we’re still spending quite a lot of time in the slow path, decoding UTF-8.
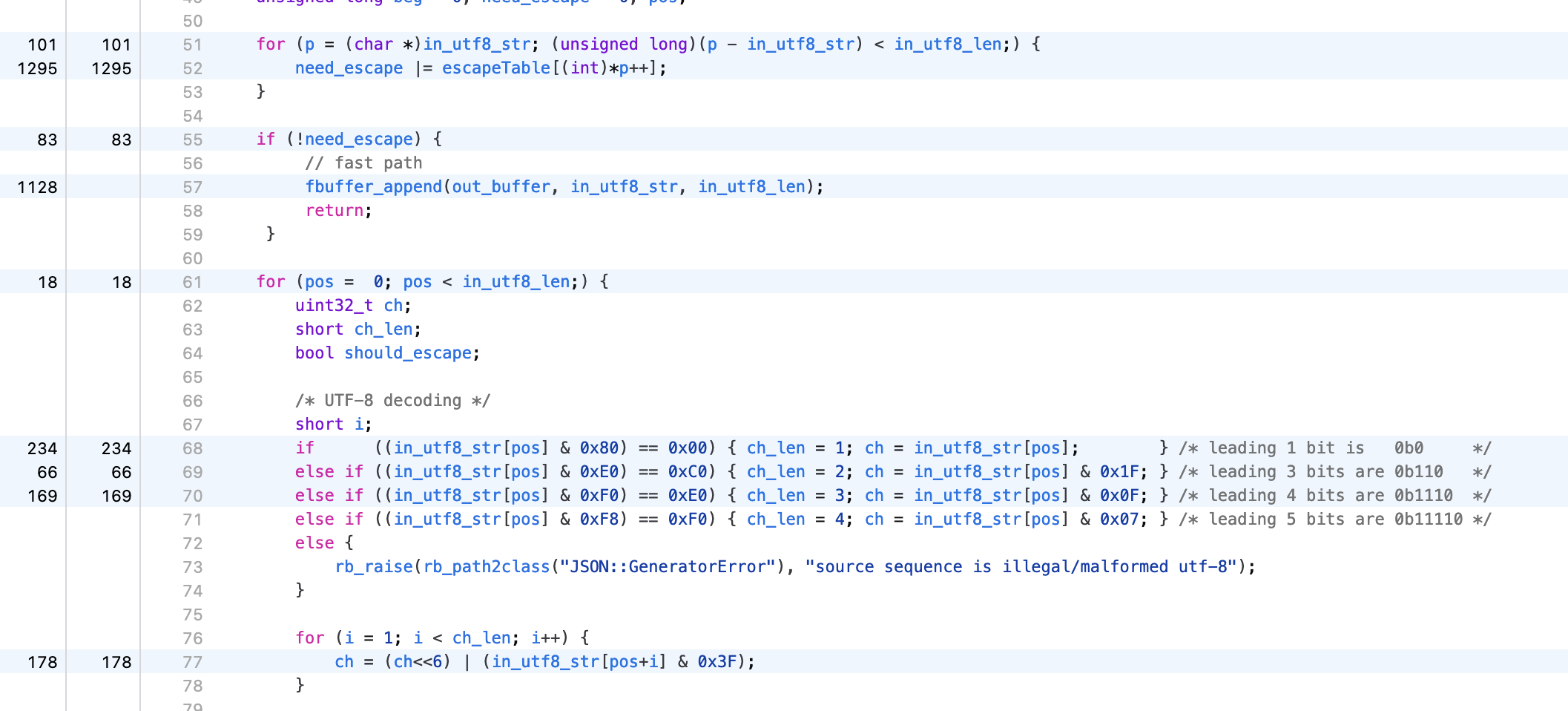
That’s because the twitter.json payload happens to contain mostly Japanese tweets, hence it’s quite UTF-8
heavy, but that’s good, it means it’s not only benchmarking the happy path.
That said, even in this case, actual UTF-8 strings are the minority in the document, most of them are pure ASCII, as such it would be interesting not to bother decoding UTF-8 at all when we know the string is plain ASCII.
As mentioned in part 1, we already know if the string is pure ASCII upfront, because we asked Ruby to compute the string coderange.
But you may also wonder, why we even bother decoding UTF-8, after all, UTF-8 is a superset of ASCII, and all we care about are \ and " characters
as well as characters that are < 0x20. That’s the nice thing with UTF-8, any code that only knows about ASCII will be compatible with UTF-8 as long
as it ignores characters outside the ASCII range.
But the reason we need to care about UTF-8 is the script_safe: true option. On paper, JSON is an extremely simple spec, but it also somewhat claims
to be a subset of JavaScript, hence you may want to interpolate some JSON inside JavaScript as a way to pass data from Ruby to JS. e.g.
<script>
MyLibrary.configure(<%= MyLib::CONFIG.to_json %>);
</script>And this works well except that you need to escape more characters. First forward slashes (/) to prevent XSS, we touched on that in part 1, but
also two weird characters, the infamous U+2028 and U+2029 characters aka Line Separator and Paragraph Separator.
The ECMAScript standard specifies that these two characters are treated as new lines, and you can’t put newlines in a JavaScript string so you end up with some syntax errors.
So if you plan to embed your JSON in JS, you need to care about characters outside the ASCII range, but here again, this is the exception, not the common case, as such we should be able to implement a fast path that doesn’t care about that.
You can see the full commit on GitHub,
but the key part can be understood by just looking at generate_json_string. Now it dispatches to a much simpler convert_ASCII_to_JSON
when possible.
static void generate_json_string(FBuffer *buffer, VALUE Vstate, JSON_Generator_State *state, VALUE obj)
{
if (!enc_utf8_compatible_p(RB_ENCODING_GET(obj))) {
obj = rb_str_export_to_enc(obj, rb_utf8_encoding());
}
fbuffer_append_char(buffer, '"');
switch(rb_enc_str_coderange(obj)) {
case ENC_CODERANGE_7BIT:
convert_ASCII_to_JSON(buffer, obj, state->script_safe);
break;
case ENC_CODERANGE_VALID:
if (RB_UNLIKELY(state->ascii_only)) {
convert_UTF8_to_ASCII_only_JSON(buffer, obj, state->script_safe);
} else {
convert_UTF8_to_JSON(buffer, obj, state->script_safe);
}
break;
default:
rb_raise(rb_path2class("JSON::GeneratorError"), "source sequence is illegal/malformed utf-8");
break;
}
fbuffer_append_char(buffer, '"');
}And it had a pretty nice impact:
== Encoding twitter.json (466906 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 189.000 i/100ms
Calculating -------------------------------------
after 1.894k (± 1.2%) i/s (527.87 μs/i) - 9.639k in 5.088860s
Comparison:
before: 1489.1 i/s
after: 1894.4 i/s - 1.27x faster
Note: because Mame’s lookup table patch was almost a year old when I took over the gem, it had to be rebased
and adapted quite a bit, so in reality, Mame’s lookup table patch was applied after this split of convert_UTF8_to_JSON
as part of a PR that combined both.
If the two commits had been applied in the opposite order I suspect my patch’s impact would have been much smaller, if not null.
The logical followup would have been to also make optimized versions of convert_ methods, that assume script_safe = false,
allowing to get one more conditional out of the loop. But I didn’t want to have to maintain this many versions of the same subroutine,
as it was already a bit tedious. And anyway, I already had another idea.
Don’t Ignore the “Not So Happy” Path
While we can expect most JSON strings to be ASCII only, we can also likely assume that even in strings that aren’t pure ASCII, most of the characters still are in the ASCII range.
The twitter.json benchmark is a total counter-example because all strings in it are either English or Japanese, so either full ASCII
or close to no ASCII at all.
But over a larger corpus, you’d likely see strings that are mostly ASCII, but a few of them might contain an accent or some symbol.
Even English texts will often contain a couple of characters outside the ASCII range, be it some emojis or some word borrowed from
French to look fancy.
A good example of that is the ctim_catalog.json benchmark, which contains some French language strings:
// ...
"areaNames": {
"205705993": "Arrière-scène central",
"205705994": "1er balcon central",
"205705995": "2ème balcon bergerie cour",
"205705996": "2ème balcon bergerie jardin",
"205705998": "1er balcon bergerie jardin",
"205705999": "1er balcon bergerie cour",
"205706000": "Arrière-scène jardin",
"205706001": "Arrière-scène cour",
"205706002": "2ème balcon jardin",
"205706003": "2ème balcon cour",
"205706004": "2ème Balcon central",
"205706005": "1er balcon jardin",
"205706006": "1er balcon cour",
"205706007": "Orchestre central",
"205706008": "Orchestre jardin",
"205706009": "Orchestre cour",
"342752287": "Zone physique secrète"
},To make it easier to profile convert_UTF8_to_JSON in this particular case, I added another micro-benchmark in the suite:
benchmark_encoding "mixed utf8", ([("a" * 5000) + "€" + ("a" * 5000)] * 500)It’s a 10kiB string, with just one character outside the ASCII range, and repeated 500 times to reduce
the relative cost of the setup, giving me a profile with 91% of the time spent inside convert_UTF8_to_JSON
and a pretty clear heatmap:
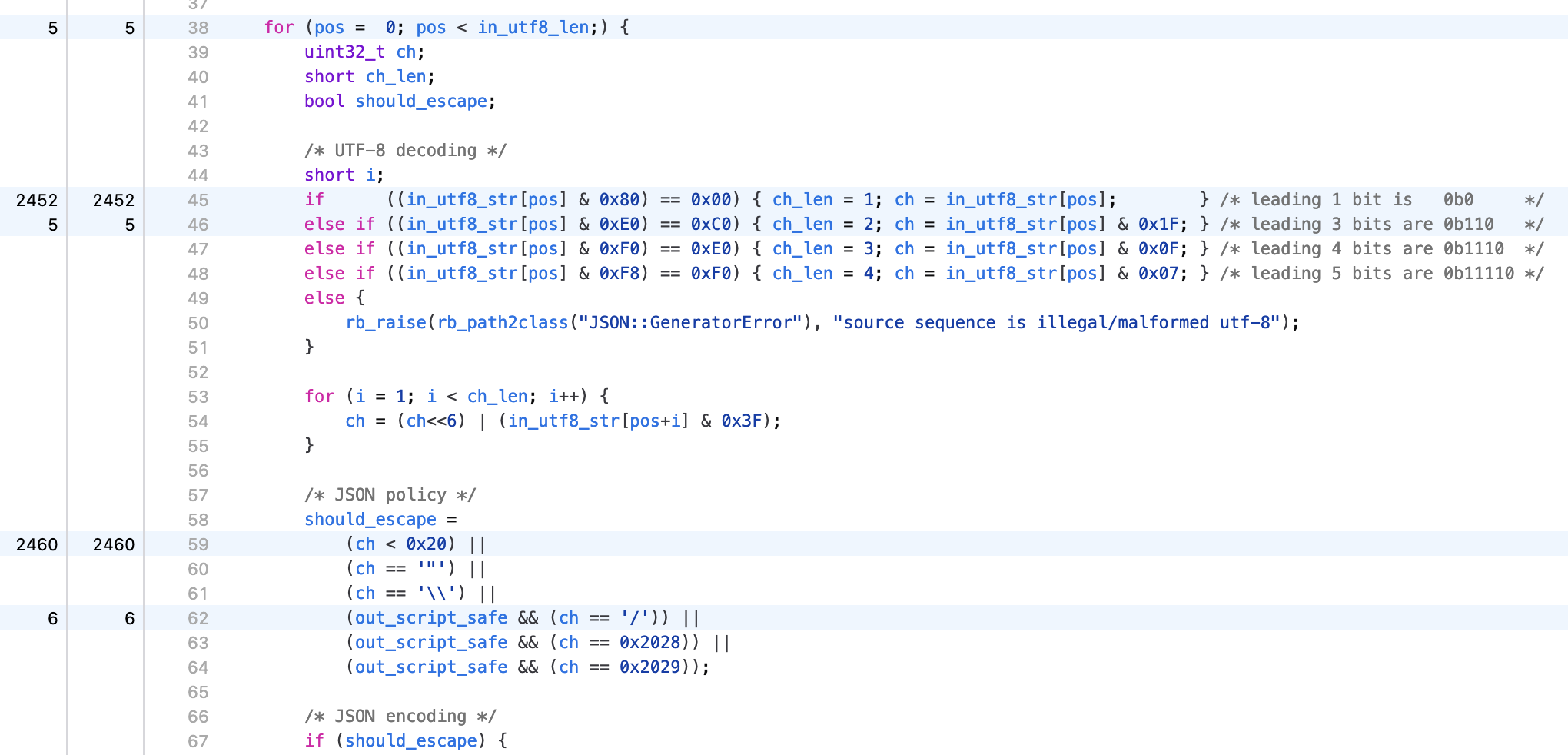
All this code had recently been rewritten pretty much from scratch by Luke Shumaker to resolve some potential licensing issues with the original code from the early days of the gem. It’s a fairly clear and straightforward implementation that first decodes UTF-8 bytes into 32-bit codepoints, then checks whether escaping is needed. If it is, we’d then copy all the scanned bytes into the buffer, followed by the escaped character. Otherwise, the loop would just continue onto the next codepoint.
While this code is very clean and generic, with a good separation of the multiple levels of abstractions, such as bytes and codepoints,
that would make it very easy to extend the escaping logic,
it isn’t taking advantage of many assumptions convert_UTF8_to_JSON could make to take shortcuts.
One of these for instance is that there’s no point validating the UTF-8 encoding because Ruby did it for us and it’s impossible to end up inside
convert_UTF8_to_JSON with invalid UTF-8.
Another is that there are only two multi-byte characters we care about, and both start with the same 0xE2 byte, so the decoding into codepoints is a bit superfluous.
So what can we do about it? Well, the same thing we do every day Pinky, eliminate conditionals.
You can see the full pull request, but let me try to explain what it does.
To replace the complex conditional that defines if the character needs to be escaped, we can re-use Mame’s lookup table, but with a twist. Instead of only storing a boolean, which tells us if the character needs to be escaped or not, we can also pack the character length.
Wikipedia has a pretty good table to understand how UTF-8 works:
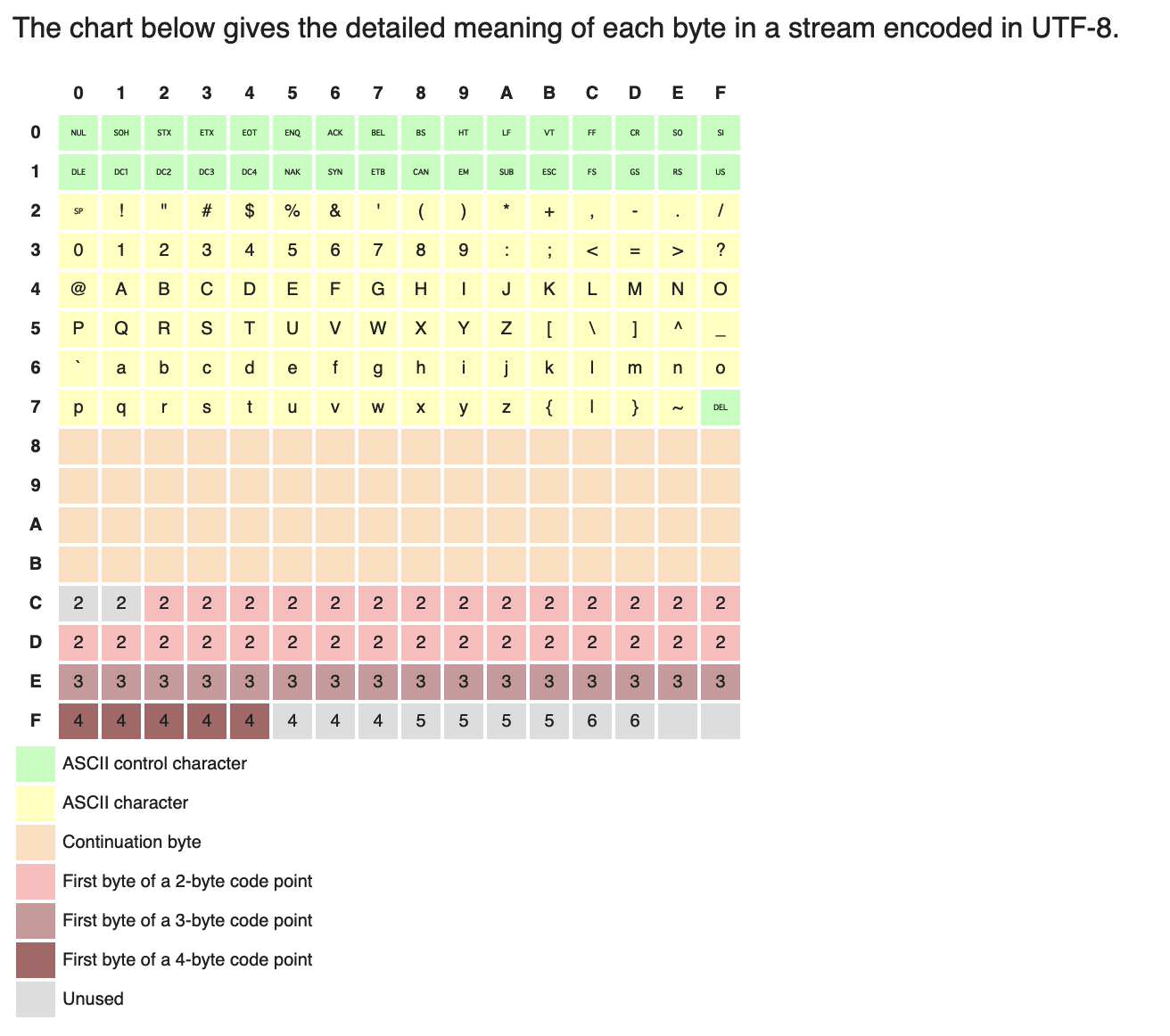
If we turn this into a lookup table, with just one pointer offset we can efficiently figure out for each byte if it needs to be escaped or if we have to deal with a multi-byte character:
static const char escape_table[256] = {
// ASCII Control Characters
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
// ASCII Characters
0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0, // '"'
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0, // '\\'
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
// Continuation byte
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
// First byte of a 2-byte code point
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
// First byte of a 4-byte code point
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
//First byte of a 4+byte code point
4,4,4,4,4,4,4,4,5,5,5,5,6,6,1,1,
};0 here means a single-byte character that doesn’t require escaping, and >= 2 means a multi-byte character.
We also have a second version of that table for the script_safe: true escaping mode, with forward-slash (/) set to 1,
and convert_UTF8_to_JSON takes the table to use as an argument.
In pseudo-Ruby, the function would now look like this:
def convert_UTF8_to_JSON(string, lookup_table)
buffer = +""
beginning = 0
position = 0
while position < string.bytesize
byte = string.getbyte(position)
if escape = lookup_table[byte]
case escape
when 1
# Copy all the bytes we saw didn't need escaping
buffer << string.byteslice(beginning..position)
buffer << escape(byte)
position += 1
beginning = position
when 3
if script_safe? && byte == 0xE2 && string.getbyte(position + 1) == ...
buffer << string.byteslice(beginning..position)
buffer << escape(byte)
position += 3
beginning = position
end
else
position += escape
end
else
position += 1
end
end
endSince our assumption is that the overwhelming majority of characters don’t need escaping and are single bytes,
for most iterations, we’re not even going to enter the if escape condition.
This resulted in the new micro-benchmark being sped up by more than 2x:
== Encoding mixed utf8 (5003001 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 37.000 i/100ms
Calculating -------------------------------------
after 439.128 (± 8.7%) i/s (2.28 ms/i) - 2.183k in 5.012174s
Comparison:
before: 194.6 i/s
after: 439.1 i/s - 2.26x faster
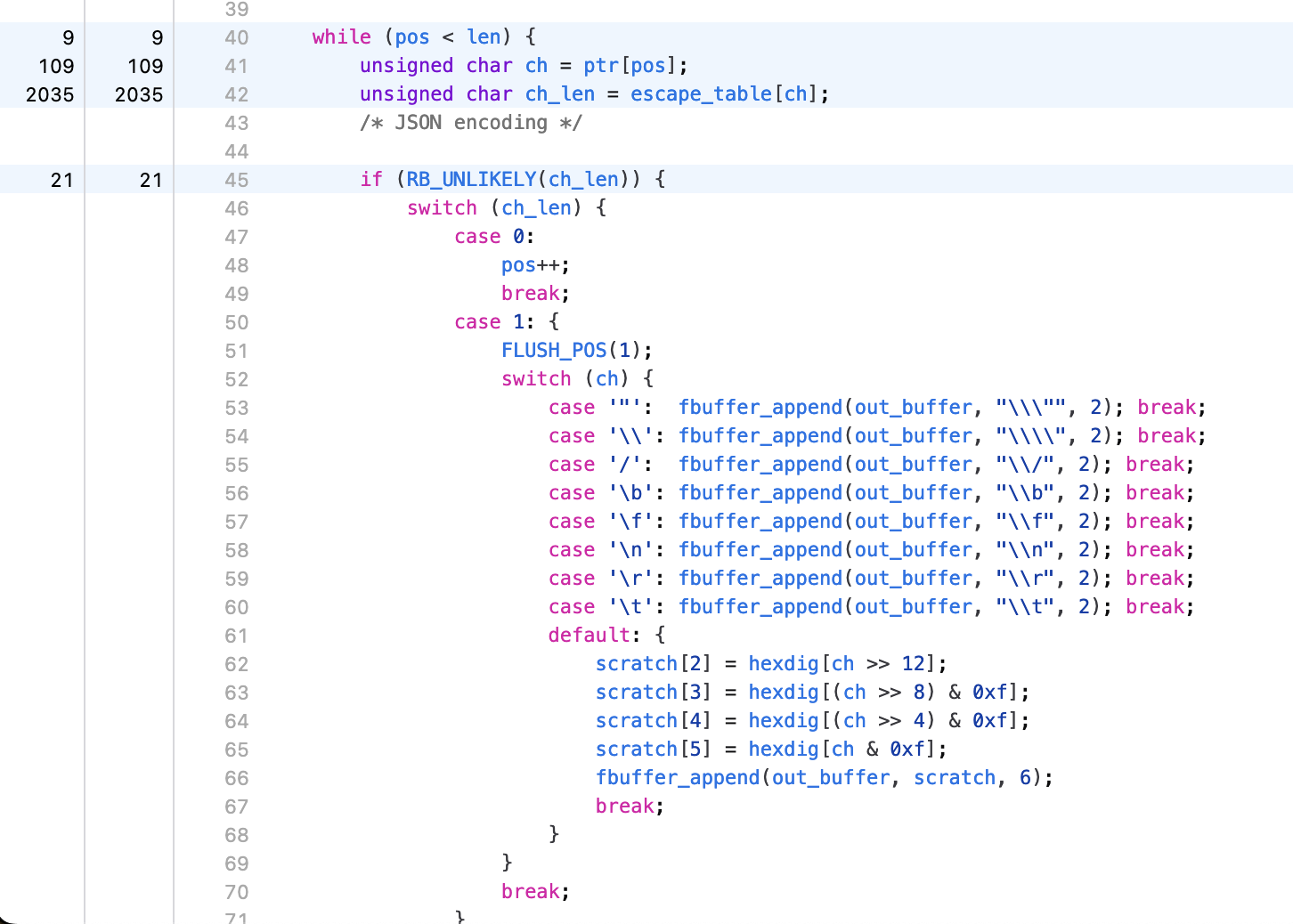
And the function heatmap shows that we’re now down to pretty much just table lookups:
However, this, unfortunately, didn’t translate in a particularly measurable gain on the macro-benchmarks, even ctim_catalog.json:
== Encoding citm_catalog.json (500298 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 132.000 i/100ms
Calculating -------------------------------------
after 1.351k (± 0.5%) i/s (739.92 μs/i) - 6.864k in 5.078953s
Comparison:
before: 1330.9 i/s
after: 1351.5 i/s - 1.02x faster
It doesn’t mean it wasn’t worth optimizing, but I misjudged how much time was spent dealing with this sort of mixed strings, and should have prioritized another hostspot. But I still merged the improvements, because benchmarks are just arbitrary workloads, someone out there might significantly benefit from the improvement.
I also realize now that I’m writing this, that I could have used something other than 3 in the lookup table for 0xE2 so that we don’t
do any extra work for the 15 other bytes that mark the start of a 3-byte wide codepoint we’re not interested in, and also so that only the
script safe version of the escape table would ever enter this branch of the code.
Micro-Benchmarks Shouldn’t Matter, But Clearly They Do
At that point, ruby/json was now on par with alternatives on macro-benchmarks, and I didn’t have any more immediate ideas on how to speed it up
further.
We were still very significantly slower on micro-benchmarks, but micro-benchmarks as explained before were simply dominated by allocations, and because
of the API exposed by ruby/json we have to allocate one more object than oj, so it’s just impossible to match its performance there.
But to me, that wasn’t a big deal, because micro-benchmarks are nowhere near indicative of real-world performance. As demonstrated above, they can be useful to help focus on optimizing a specific part of a larger system, but other than that, they don’t serve any actual purpose. Unless of course online flamewars on who got the fastest is your purpose.
Additionally, if somehow you needed to generate a lot of small documents, you could use a lower-level API to elide that allocation,
by reusing the Generator::State object:
state = JSON::State.new(JSON.dump_default_options)
state.generate(ruby_obj)
state.generate(another_obj)Using this API, ruby/json was very much on par with alternatives:
== Encoding small nested array (121 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
oj 223.200k i/100ms
json 167.997k i/100ms
json (reuse) 237.781k i/100ms
Calculating -------------------------------------
oj 2.295M (± 1.2%) i/s (435.64 ns/i) - 11.606M in 5.056904s
json 1.742M (± 0.2%) i/s (574.13 ns/i) - 8.736M in 5.015536s
json (reuse) 2.449M (± 0.2%) i/s (408.28 ns/i) - 12.365M in 5.048249s
Comparison:
oj: 2295492.3 i/s
json (reuse): 2449294.2 i/s - 1.07x faster
json: 1741765.4 i/s - 1.32x slower
== Encoding small hash (65 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
oj 676.718k i/100ms
json 269.175k i/100ms
json (reuse) 500.536k i/100ms
Calculating -------------------------------------
oj 7.305M (± 0.3%) i/s (136.90 ns/i) - 36.543M in 5.002601s
json 2.855M (± 0.2%) i/s (350.23 ns/i) - 14.535M in 5.090715s
json (reuse) 5.371M (± 3.7%) i/s (186.18 ns/i) - 27.029M in 5.041441s
Comparison:
oj: 7304845.2 i/s
json (reuse): 5371216.1 i/s - 1.36x slower
json: 2855303.9 i/s - 2.56x slower
So I started working on releasing json 2.7.3, and announced that from now on, I’d consider
significant performance differences on realistic benchmarks a bug.
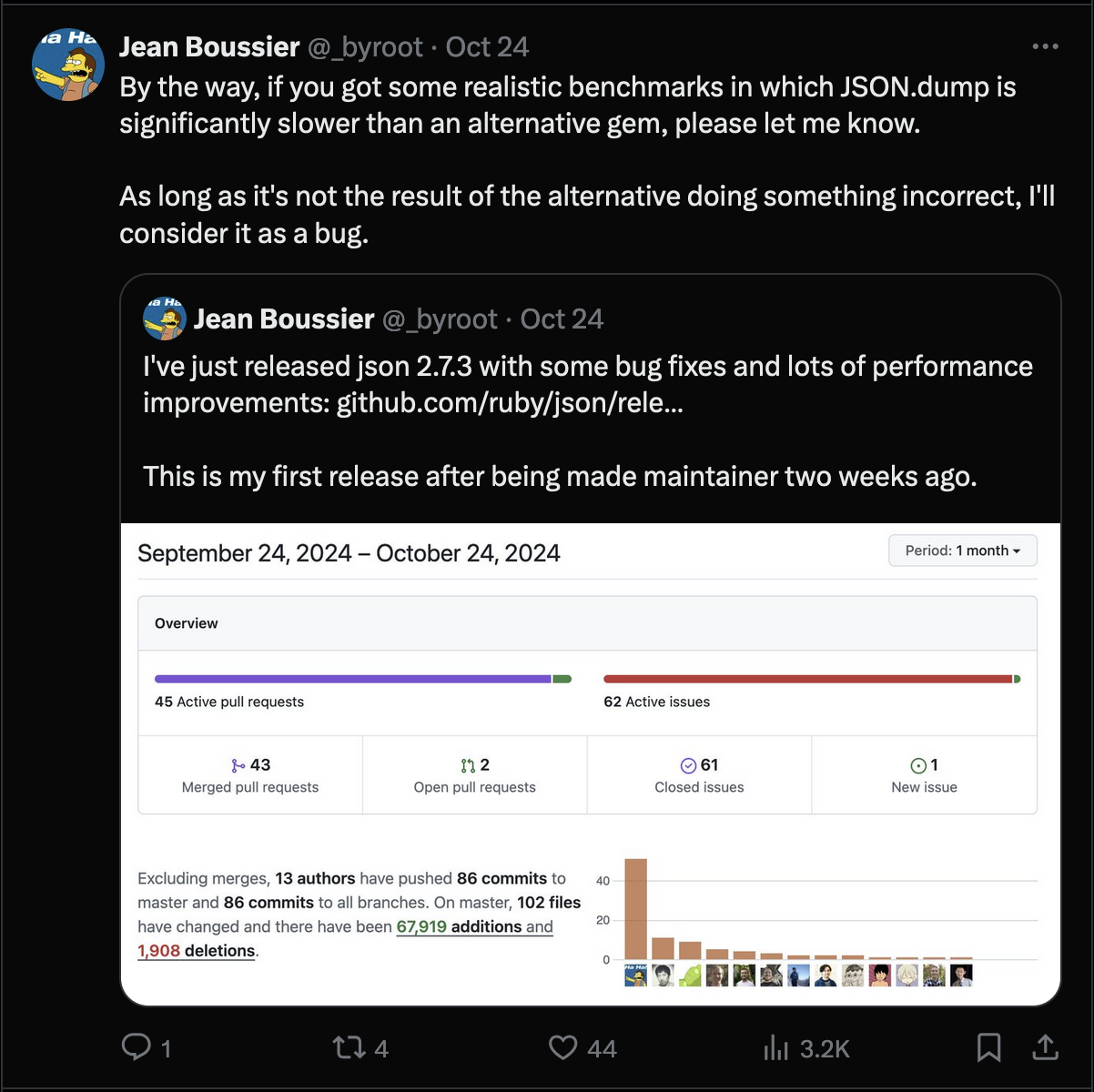
I specifically said realistic, because I had no intention to spent time optimizing for what I consider to be unrealistic micro-benchmarks.
And yet, I pretty quickly got a response saying ruby/json was 3x slower than oj:
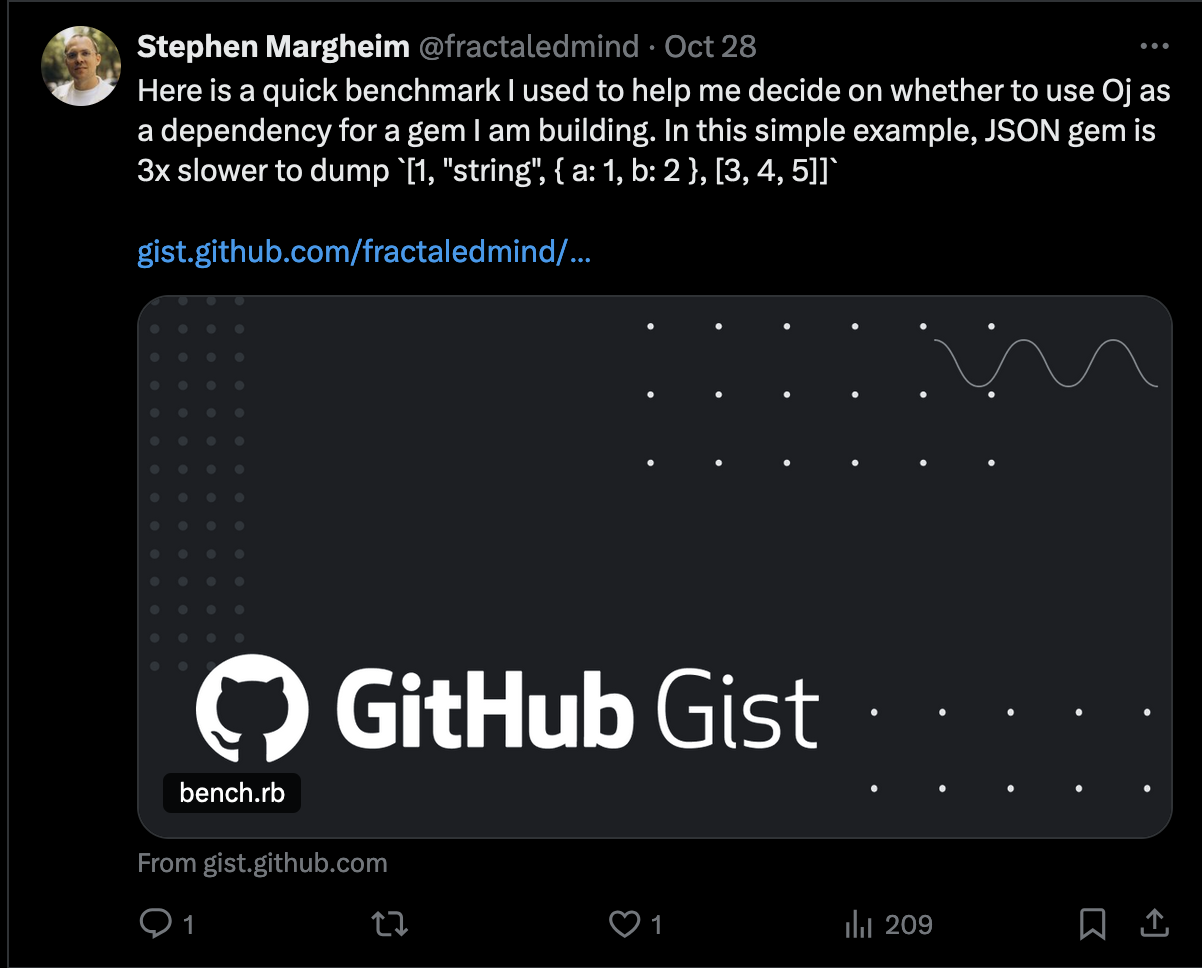
So clearly, no amount of communication on how micro-benchmarks don’t matter would be enough to change people’s perceptions.
If I wanted the public perception to change, I had to make ruby/json faster on micro-benchmarks too, and that meant
reducing the setup cost even further. But that’s a story for the next post.
To Be Continued
In the next post, we’ll dive into how the setup cost was optimized further, and then at some point, we’ll have to start talking about optimizing the parser.
Edit: Part four is here.