Optimizing Ruby's JSON, Part 2
In the previous post, I covered my motivations for improving ruby/json’s performance,
and detailed the first 4 notable optimizations applied to speed up JSON generation.
If I was to cover every single optimization applied, at this rate I’d end up with a dozen parts, so I’ll try to only focus on the one that made a significant difference or used an interesting pattern.
Reducing Setup Cost - Argument Parsing Edition
As mentioned in Part 1, When your benchmark only serializes a few dozen bytes of JSON, you end up measuring the baseline overhead of operations needed before you get to the actual work you’re here to perform, what I call “setup cost”.
The very high setup cost of ruby/json made it perform poorly on micro-benchmarks compared to alternatives.
If you look at the native profile of JSON.dump([1, "string", { a: 1, b: 2 }, [3, 4, 5]]),
you can see that we only spend 39% of the time in cState_generate which is where we’re actually generating JSON, everything else is the setup cost.
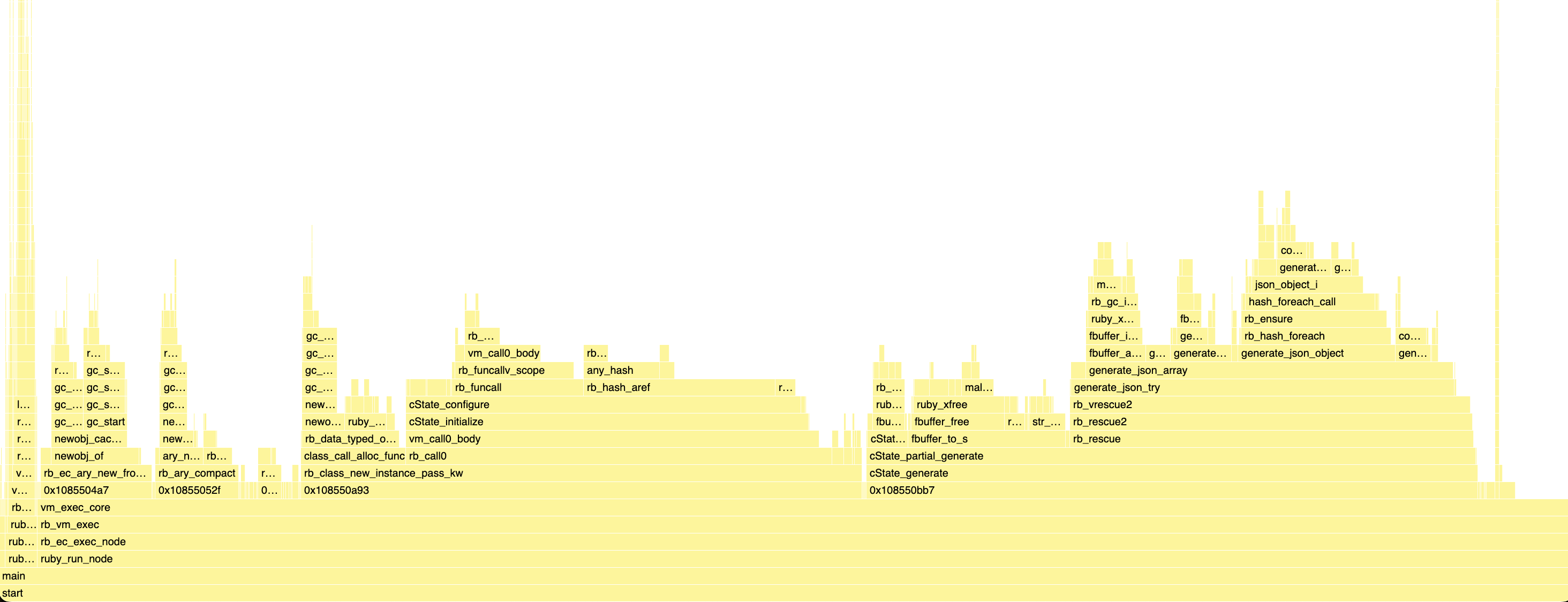
So if we want to make ruby/json look good on micro-benchmarks, the setup cost is what need to be reduced.
And a big part of that was how JSON.dump parses the arguments it receives, because JSON.dump is one of these cursed methods that can be used in
way too many different ways. Aside from the first argument which is the object to serialize, dump accepts 3 positional arguments that are all optional.
In RDoc style, the signature would be dump(obj, [anIo], [depth_limit], [options]). This sort of signature is quite common in old gems that predate the
introduction of keyword arguments back in Ruby 2.0, and often cause an explosion of call patterns.
Here are 7 different ways the method can be called.
JSON.dump({}) # => "{}"
JSON.dump({}, 12) # => "{}"
JSON.dump({}, 12, strict: true) # => "{}"
JSON.dump({}, File.open("/tmp/foo.json", "w+")) # => #<File:/tmp/foo.json>
JSON.dump({}, File.open("/tmp/foo.json", "w+"), 12) # => #<File:/tmp/foo.json>
JSON.dump({}, File.open("/tmp/foo.json", "w+"), 12, strict: true) # => #<File:/tmp/foo.json>
JSON.dump({}, File.open("/tmp/foo.json", "w+"), strict: true) # => #<File:/tmp/foo.json>Here’s how the argument parsing was implemented:
def dump(obj, anIO = nil, limit = nil, kwargs = nil)
io_limit_opt = [anIO, limit, kwargs].compact
kwargs = io_limit_opt.pop if io_limit_opt.last.is_a?(Hash)
anIO, limit = io_limit_opt
if anIO.respond_to?(:to_io)
anIO = anIO.to_io
elsif limit.nil? && !anIO.respond_to?(:write)
anIO, limit = nil, anIO
end
opts = JSON.dump_default_options
opts = opts.merge(:max_nesting => limit) if limit
opts = merge_dump_options(opts, **kwargs) if kwargs
result = generate(obj, opts)
if anIO
anIO.write result
anIO
else
result
end
rescue JSON::NestingError
raise ArgumentError, "exceed depth limit"
endThere are a number of operations in there that are reasonably costly in abstract, but costly enough that you don’t want to use them in hot spots.
The first one is [anIO, limit, kwargs].compact, which is used to ignore nil arguments. It’s quite pleasing to the eye, and fairly idiomatic Ruby,
but it means one extra allocation, which is a lot on micro-benchmarks.
The alternative we’re trying to catch up to, only allocates a single object on its equivalent path, the returned JSON document as a String.
But ruby/json also need to allocate the JSON::Generator::State object, so that’s a total of 3 allocations, 3 times as much as oj or rapidjson-ruby.
Allocations aren’t that big of a problem on modern Ruby, it’s actually quite fast, the problem is that allocating will ultimately trigger the GC, and while that too is negligible when doing a meaningful amount of work, it’s a huge proportion of the runtime in a micro-benchmark.
Then, there’s the respond_to?(:to_io) call (and sometimes the second one), which too is totally mundane and idiomatic Ruby code, but something
you want to avoid in hot paths.
respond_to? does all the same work a method call does to find which method to call, but the major difference is that method calls have an inline cache
while respond_to? doesn’t, so it has to do more work than most method calls.
Method Lookup
To give you an idea of how much work looking up a method without a cache can entail, here is what it would look like if implemented in Ruby
class Object
def respond_to?(method)
self.class.ancestors.each do |ancestor|
return true if ancestor.methods_hash.key?(method)
end
# object doesn't respond to `method` but maybe it has a `respond_to_missing?` method.
self.class.ancestors.each do |ancestor|
if respond_to_missing = ancestor.methods_hash[:respond_to_missing?]
return respond_to_missing.bind_call(self, method)
end
end
false
end
endIf you assume most of the time anIO is nil, that’s a lot of needless hash lookups, because nil has way more ancestors than you’d think:
p nil.class.ancestors.size # => 4
require "json"
p nil.class.ancestors.size # => 6
require "active_support/all"
p nil.class.ancestors.size # => 9And on a miss, you might actually have to do all that a second time, to check if perhaps that class implements #respond_to_missing.
As mentioned, calling a method conceptually requires as much work, however, most method calls don’t result in a NoMethodError so you normally don’t
go all the way up the ancestor chain, and more importantly method calls have inline caches.
Inline Caches
I touched a bit on what inline caches are last year in my post about object shapes, but to reiterate here, when Ruby compiles your code into YARV bytecode, for every method call it leaves a little bit of space called an inline cache.
For instance, if Ruby has to execute nil.bar, it will compile that into an opt_send_without_block instruction:
>> puts RubyVM::InstructionSequence.compile(%{nil.bar}).disasm
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(1,7)>
0000 putnil ( 1)[Li]
0001 opt_send_without_block <calldata!mid:bar, argc:0, ARGS_SIMPLE>
0003 leaveWhich down the line will end up in vm_search_method_fastpath, that has access to cc AKA a “callcache”.
The actual method is a bit hard to read with lots of asserts etc, but here’s a stripped-down version that should be easy to understand:
static const struct rb_callcache *
vm_search_method_fastpath(VALUE cd_owner, struct rb_call_data *cd, VALUE klass)
{
const struct rb_callcache *cc = cd->cc;
if (LIKELY(cc->klass == klass)) {
if (LIKELY(!(cc->cme->flags & INVALIDATED_FLAG)))) {
return cc;
}
}
return vm_search_method_slowpath0(cd_owner, cd, klass);
}So in short, every single call site has a cache that contains the class of the last object this method was called on, and the result of the previous search.
Revalidating that cache is just a simple pointer comparison to ensure we’re still dealing with an instance of the same class,
and a check in a bitmap to ensure the cache wasn’t invalidated by something like define_method or remove_method.
That is a ton less work than the slow path, and since in practice most call sites are “monomorphic”, meaning they only ever apply to a single type, this cache hit rate is fairly high.
The problem with respond_to? is that the name of the method we’re looking for is passed as an argument:
>> puts RubyVM::InstructionSequence.compile(%{nil.respond_to?(:bar)}).disasm
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(1,21)>
0000 putnil ( 1)[Li]
0001 putobject :bar
0003 opt_send_without_block <calldata!mid:respond_to?, argc:1, ARGS_SIMPLE>
0005 leaveSo here we have a call cache to lookup respond_to? on nil, but nowhere to cache the lookup of bar.
It actually wouldn’t be too hard to add such a cache, we’d need to modify the Ruby compiler to compile
respond_to? calls into a specialized opt_respond_to instruction that does have two caches instead of one.
The first cache would be used to look up respond_to? on the object to make sure it wasn’t redefined,
and the second one to look up the method we’re interested in. Or perhaps even 3 caches, as you also need to
check if the object has a respond_to_missing? method defined in some cases.
That’s an idea I remember discussing in the past with some fellow committers, but I can’t quite remember if there was a reason we didn’t do it yet.
Nested Caching
That said, even without inline caches, respond_to? usually avoids doing the full method lookup.
Given how horrendously expensive they are, method lookups have two layers of cache.
Inside the Class object structure, there is a field called cc_tbl for “call cache table”.
That’s essentially a Hash with method names as keys, and “call caches” as values.
So respond_to?’s implementation is actually more like this:
class Object
def respond_to?(method)
cc = self.class.call_cache[method]
if method_entry = self.class.search_method_with_cache(method, cc)
return true
end
respond_to_missing_cc = self.class.call_cache[method]
if respond_to_missing = self.class.search_method_with_cache(:respond_to_missing?, cc)
return respond_to_missing.bind_call(self, method)
end
false
end
endSo it’s thankfully much less work than an uncached method lookup, but when respond_to? returns false
we’re still doing at least two hash lookups to get the corresponding call caches.
So you can see how calling respond_to? on nil is a bit of a waste.
Cheaper Argument Parsing
But enough digression, and back to the problem at hand.
In most cases, none of these options are set, so the goal is to avoid allocating an array,
and avoid respond_to? when possible, which led me to rewrite dump as this:
def dump(obj, anIO = nil, limit = nil, kwargs = nil)
if kwargs.nil?
if limit.nil?
if anIO.is_a?(Hash)
kwargs = anIO
anIO = nil
end
elsif limit.is_a?(Hash)
kwargs = limit
limit = nil
end
end
unless anIO.nil?
if anIO.respond_to?(:to_io)
anIO = anIO.to_io
elsif limit.nil? && !anIO.respond_to?(:write)
anIO, limit = nil, anIO
end
end
opts = JSON.dump_default_options
opts = opts.merge(:max_nesting => limit) if limit
opts = merge_dump_options(opts, **kwargs) if kwargs
begin
if State === opts
opts.generate(obj, anIO)
else
State.generate(obj, opts, anIO)
end
rescue JSON::NestingError
raise ArgumentError, "exceed depth limit"
end
endSo instead of using Array#compact, we do multiple nested if thing.nil? checks. It’s more verbose, but much more efficient, allocations
free, and JIT very well.
The is_a?(Hash) calls are no performance concern on Ruby 3.2+ thanks to John Hawthorn’s stellar work, so they can stay.
As for respond_to?, we can’t fully eliminate it, but at least we can avoid calling it when the variable is nil, which should be most of the time.
All this combined yielded a nice 16% improvement on micro benchmarks:
== Encoding small mixed (34 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 227.226k i/100ms
Calculating -------------------------------------
after 2.415M (± 0.9%) i/s (414.02 ns/i) - 12.270M in 5.080537s
Comparison:
before: 2078464.1 i/s
after: 2415336.1 i/s - 1.16x faster
After I merged that patch, Benoit Daloze a fellow Ruby committer and TruffleRuby lead, suggested a funny trick that is used very effectively in the Ruby stdlib for optimizing this sort of signature:
def dump(obj, anIO = (no_args_set = true; nil), limit = nil, kwargs = nil)
unless no_args_set
# do the whole argument parsing
end
# ...
endI love that trick because it exploits the fact that, like pretty much everything in Ruby, arguments’ default values are expressions.
This trick is most commonly used when you need to know if an argument was passed as nil or just not passed, an example of that
is Hash#initialize
class Hash
def initialize(ifnone = (ifnone_unset = true), capacity: 0, &block)
Primitive.rb_hash_init(capacity, ifnone_unset, ifnone, block)
end
endIf it used the classic ifnone = nil signature, it wouldn’t be possible to differentiate Hash.new and Hash.new(nil).
However in this case that trick didn’t make a measurable difference, so I didn’t include that suggestion, but I thought it was worth a mention.
Jump Tables
The previous optimization helped with the setup cost, but it was still way more expensive than it should.
So I went to craft an even more micro-benchmark, trying to reduce the time spent generating JSON to better see the setup cost:
require "json"
i = 20_000_000
obj = {}
while i > 0
i -= 1
JSON.dump(obj)
end
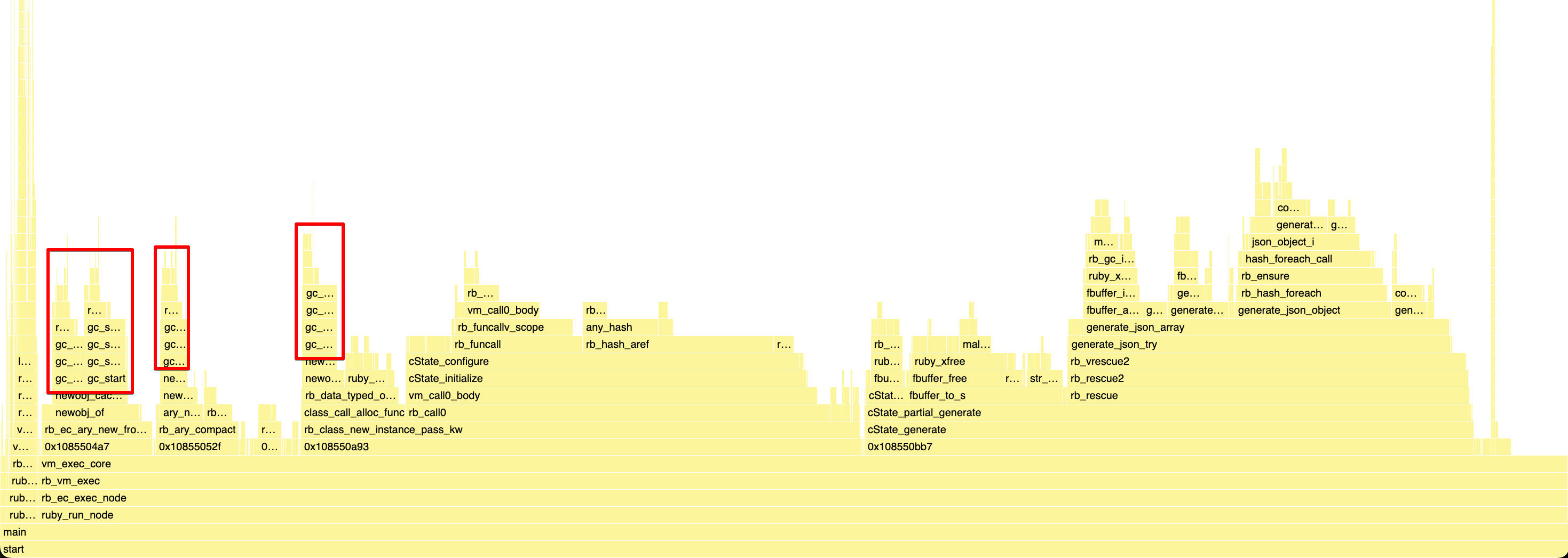
As you may have spotted on that flame graph, a huge part of the setup is spent in rb_hash_aref and rb_hash_has_key, which are the
C API equivalents of Hash#[] and Hash#key?.
And all of this was in the JSON::Generator::State#configure method, implemented in C this way:
#define option_given_p(opts, key) RTEST(rb_funcall(opts, i_key_p, 1, key))
static VALUE cState_configure(VALUE self, VALUE opts)
{
VALUE tmp;
GET_STATE(self);
tmp = rb_check_convert_type(opts, T_HASH, "Hash", "to_hash");
if (NIL_P(tmp)) tmp = rb_convert_type(opts, T_HASH, "Hash", "to_h");
opts = tmp;
tmp = rb_hash_aref(opts, ID2SYM(i_indent));
if (RTEST(tmp)) {
unsigned long len;
Check_Type(tmp, T_STRING);
len = RSTRING_LEN(tmp);
state->indent = fstrndup(RSTRING_PTR(tmp), len + 1);
state->indent_len = len;
}
tmp = rb_hash_aref(opts, ID2SYM(i_space));
if (RTEST(tmp)) {
unsigned long len;
Check_Type(tmp, T_STRING);
len = RSTRING_LEN(tmp);
state->space = fstrndup(RSTRING_PTR(tmp), len + 1);
state->space_len = len;
}
// ....
tmp = ID2SYM(i_max_nesting);
state->max_nesting = 100;
if (option_given_p(opts, tmp)) {
VALUE max_nesting = rb_hash_aref(opts, tmp);
if (RTEST(max_nesting)) {
Check_Type(max_nesting, T_FIXNUM);
state->max_nesting = FIX2LONG(max_nesting);
} else {
state->max_nesting = 0;
}
}Which again is very verbose and noisy because it’s in C, but is essentially the naive way you’d initialize some object state from an options hash:
def configure(opts)
if indent = opts[:indent]
@indent = ensure_string(indent)
end
if space = opts[:space]
@space = ensure_string(space)
end
# ...
@max_nesting = 100
if opts.key?(:max_nesting)
if max_nesting = opts[:max_nesting]
@max_nesting = Integer(max_nesting)
else
@max_nesting = 0
end
end
endgccct
On the surface, there is some weirdly inefficient code here, such as using:
RTEST(rb_funcall(opts, i_key_p, 1, key))To check if the option hash contains a key. Calling a method from C is quite costly because, you guessed it, looking up a method without a cache is costly.
Here again, we don’t have an inline cache, so Ruby has yet another trick down its sleeve to not make the performance atrocious,
the gccct. No I’m not having a stroke, it’s the acronym for “Global Call Cache Cache Table”, and yes it’s a cache of caches.
I did write a Twitter thread back in September that talked about the gccct, but since
that site is quite hostile to outsiders, I’ll repeat some of it here.
The gccct is just a big global array of exactly 1023 call_cache objects, so when you need to lookup a method and there’s no better cache you can use,
you use one of these global caches:
GLOBAL_CALL_CACHE_CACHE_TABLE_SIZE = 1023
GLOBAL_CALL_CACHE_CACHE_TABLE = Array.new(GLOBAL_CALL_CACHE_CACHE_TABLE_SIZE)
def gccct_method_search(receiver, method_name)
index = [receiver.class, method_name].hash % GLOBAL_CALL_CACHE_CACHE_TABLE_SIZE
call_cache = GLOBAL_CALL_CACHE_CACHE_TABLE[index]
cached_method_search(receiver, method_name, call_cache)
endIt’s as simple as that, we do a digest of the receiver class and the method name, and use that as an offset inside the array to select a call cache.
Of course, it can be subject to collisions, so distinct calls can end up sharing the same cache and make it flip-flop, but it still offers some decent hit rate for cheap, so it’s better than nothing.
But that’s yet another digression because ultimately we just don’t need that at all, given the C API exposes some C functions that allow us to check if a key exists without needing to go through method lookup. I suspect this may have been implemented this way a long time ago to also support Hash-like objects, but it really isn’t worth the overhead.
In another Pull Request, Luke Gruber had done a similar optimization for the parser initialization,
rewriting option_given_p into:
static VALUE hash_has_key(VALUE hash, VALUE key)
{
if (Qundef == rb_hash_lookup2(hash, key, Qundef)) {
return Qtrue;
}
return Qfalse;
}
#define option_given_p(opts, key) (RTEST(hash_has_key(opts, key)))And I could probably have done the same here, but I had another, less conventional, idea.
Inversion of Priorities
There’s probably a name for that optimization, but if so I don’t know it.
When thinking about the problem, it occurred to me that there are 13 possible option keys we need to check, but in the vast majority of cases, the hash will only contain a few of them.
By default JSON.dump starts from the JSON.dump_default_options global config, so if you call dump with no extra options, that’s what we’ll get:
self.dump_default_options = {
:max_nesting => false,
:allow_nan => true,
:script_safe => false,
}Actually, out of these 3 keys, the third one is useless, as it’s already the default, so really most of the time we only have two keys to check.
So what if instead of doing one to two lookups for every possible key (13), we’d iterate over the provided keys and use a jump table?
The problem, however, is to do jump tables in C, you need a switch statement with static values, and hash keys are Ruby symbol objects, hence we can’t statically
know their value because they’re defined at runtime.
switch(key) {
case sym_max_nesting: // This is just not possible...
break;
}But what few people know, is that Ruby’s case statement do generate a jump table when possible. Let me show you:
By default Ruby’s case just compiles down to a series of if / elsif:
puts RubyVM::InstructionSequence.compile(<<~RUBY).disasm
case key
when /foo/
something
when /bar/
something_else
end
RUBY
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(6,3)>
0000 putself ( 1)[Li]
0001 opt_send_without_block <calldata!mid:key, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0003 putobject /foo/ ( 2)
0005 topn 1
0007 opt_send_without_block <calldata!mid:===, argc:1, FCALL|ARGS_SIMPLE>
0009 branchif 22
0011 putobject /bar/ ( 4)
0013 topn 1
0015 opt_send_without_block <calldata!mid:===, argc:1, FCALL|ARGS_SIMPLE>
0017 branchif 27
0019 pop ( 1)
0020 putnil
0021 leave ( 5)
0022 pop ( 2)
0023 putself ( 3)[Li]
0024 opt_send_without_block <calldata!mid:something, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0026 leave ( 5)
0027 pop ( 4)
0028 putself ( 5)[Li]
0029 opt_send_without_block <calldata!mid:something_else, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0031 leaveIf you’re not familar with YARV assembly, here’s the “desugared” Ruby version of it:
if key === /foo/
something
elsif key === /bar/
something_else
endSo it’s not a jump table, just some syntax sugar for if / elsif.
But if all the when values are essentially static (this includes literal numbers, literal symbols and literal strings),
Ruby generates some slightly different bytecode:
puts RubyVM::InstructionSequence.compile(<<~RUBY).disasm
case key
when :foo
something
when :bar
something_else
end
RUBY
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(6,3)>
0000 putself ( 1)[Li]
0001 opt_send_without_block <calldata!mid:key, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0003 dup
0004 opt_case_dispatch <cdhash>, 23
0007 putobject :foo ( 2)
0009 topn 1
0011 opt_send_without_block <calldata!mid:===, argc:1, FCALL|ARGS_SIMPLE>
0013 branchif 26
0015 putobject :bar ( 4)
0017 topn 1
0019 opt_send_without_block <calldata!mid:===, argc:1, FCALL|ARGS_SIMPLE>
0021 branchif 31
0023 pop ( 1)
0024 putnil
0025 leave ( 5)
0026 pop ( 2)
0027 putself ( 3)[Li]
0028 opt_send_without_block <calldata!mid:something, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0030 leave ( 5)
0031 pop ( 4)
0032 putself ( 5)[Li]
0033 opt_send_without_block <calldata!mid:something_else, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0035 leaveThe thing to notice here is the opt_case_dispatch instruction, which wasn’t present on the previous disassembly.
What this instruction does, is that it holds a Hash, of which the keys are the static values we use in the when statements
and the values are the bytecode offset to which to directly jump. The rest of the bytecode is the same, to be used as the fallback
if the opt_case_dispatch doesn’t match.
With this, we can check as many symbols as we want in somewhat constant time, all we had to do was to rewrite all that nasty C code in Ruby,
which I did in the most straightforward way in a preparatory commit.
That commit alone already brought a 3% improvement, thanks to inline caches:
== Encoding small mixed (34 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 230.150k i/100ms
Calculating -------------------------------------
after 2.450M (± 0.5%) i/s (408.23 ns/i) - 12.428M in 5.073603s
Comparison:
before: 2370478.1 i/s
after: 2449616.3 i/s - 1.03x faster
But I then followed up in the same pull request, with a rewrite of State#configure to use a case dispatch:
def configure(opts)
unless opts.is_a?(Hash)
if opts.respond_to?(:to_hash)
opts = opts.to_hash
elsif opts.respond_to?(:to_h)
opts = opts.to_h
else
raise TypeError, "can't convert #{opts.class} into Hash"
end
end
opts.each do |key, value|
case key
when :indent
self.indent = value
when :space
self.space = value
# ...
end
endAnd that brought a further 11% improvement:
== Encoding small mixed (34 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 247.127k i/100ms
Calculating -------------------------------------
after 2.645M (± 0.6%) i/s (378.07 ns/i) - 13.345M in 5.045454s
Comparison:
before: 2379291.6 i/s
after: 2645019.6 i/s - 1.11x faster
So the rewrite in Ruby was a win-win, less C code to maintain, and more efficiency overall.
To Be Continued
I only talked about two small optimizations, but I digressed so much that it’s already longer than part one, and I probably won’t have time to write in the next few days, so it’s probably best if I stop here for part two.
At this rate, and based only on the number of commits I haven’t yet covered, I may need 5 or 6 more parts, but I hope I won’t have to disgress as much as the series progress, and not all commits may be worth talking about.
Edit: Part three is here.