Optimizing Ruby's JSON, Part 1
I was recently made maintainer of the json gem, and aside from fixing some old bugs, I focused quite a bit on its performance,
so that it is now the fastest JSON parser and generator for Ruby on most benchmarks.
Contrary to what one might think, there wasn’t any black magic or deep knowledge involved. Most of the performance patches I applied were fairly simple optimizations driven by profiling. As such, I’d like to go over these changes to show how they are quite generic and that many don’t only apply to C code.
But before I dive into these, let me explain why I came about working on this in the first place.
There Should Be No Need For Alternatives
My motivation was never really performance per se. ruby/json was indeed slower than popular alternatives such as oj, but not by that much.
To take one benchmark as an example, parsing a JSON document consisting of one hundred tweets or 467kiB
would take 1.9ms with json 2.7.2, and 1.6ms with oj. So not that big of a difference.
On the generation side, json 2.7.2 would take 0.8ms to generate that document, and oj would take 0.4ms.
Twice better, but unlikely to make a significant difference for the vast majority of use cases.
In general what’s slow is the layer above the JSON serialization, the one that turns Active Record models into basic Ruby Hashes and Arrays to feed them to the JSON serializer.
But the JSON serializer itself is generally negligible.
And yet, oj is extremely popular, I highly suspect because of its speed, and is included in the vast majority of projects I know, including Shopify’s codebase, and that annoys me.
This may surprise you, given generally when oj is mentioned online, all you can read is praises and how it’s just “free performance”, but my opinion differs very significantly here.
Why? Because oj has caused me innumerable headaches over the years, so many I couldn’t list them all here, but I can mention a few.
With Monkey Patching Comes Great Responsibility
One way oj is frequently used is by monkey patching the json gem via Oj.mimic_JSON or ActiveSupport::JSON via Oj.optimize_rails.
The premise of these methods is that they’re supposed to replace less efficient implementations of JSON and do the same thing but faster. For the most part, it holds true, but in some cases, it can go terribly wrong.
For instance, one day I had to deal with a security issue caused by Oj.mimic_json.
One gem was using JSON.dump(data, script_safe: true), to safely include a JSON document inside a <script> tag:
JSON.generate("</script>") # => </script>
JSON.generate("</script>", script_safe: true) # => <\/script>Except that oj doesn’t know about the script_safe option, and simply ignores it. So the gem was safe when ran alone,
but once used in an application that called Oj.mimic_JSON, it would open the door to XSS attacks…:
Oj.mimic_JSON
JSON.generate("</script>", script_safe: true) # => </script>This isn’t to say monkey patching is wrong in essence, but it should be done with great care, considering how the patched API may evolve in the future and how to safety fallback or at least explictly error when something is amiss.
Oj.optimize_rails similarly can cause some very subtle differences in how objects are serialized, e.g.
ActiveSupport::JSON::Encoding.time_precision = 0
t = Time.now
puts ActiveSupport::JSON.encode(t) # => "2024-12-16T16:00:51+01:00"
require 'oj'
Oj.optimize_rails
Oj.mimic_JSON
puts ActiveSupport::JSON.encode(t) # => "2024-12-16T16:00:51.790+01:00"This one is a bit of a corner case caused by load order, but I had to waste a lot of time fighting with it in the past. And until very recently, it changed the behavior way more than that.
Quite Unstable
Another big reason I don’t recommend oj is that from my experience of running it at scale, it has been one of the most prominent sources of
Ruby crashes for us, only second to grpc.
I and my teammates had to submit quite several patches for weird crashes we ran into, which in itself isn’t a red flag,
as we did as much for many other native gems, but oj is very actively developed, so we’d often run into new crashes and never
felt like the gem was fixed.
Writing a native gem isn’t inherently hard, but it does require some substantial understanding of how the Ruby VM works, especially its GC,
to not cause crashes or worse, memory corruption.
And while working on these patches for Oj, we’ve seen quite a few dirty hacks in the codebase that made us worried about trusting it.
Just to give an example (that has been thankfully fixed since), oj used to disable GC in some cases to workaround a bug,
which in addition to being worrying, also causes a major GC cycle to be triggered when GC is re-enabled later.
This is the sort of code that makes for great results on micro-benchmarks, but tank performance in actual production code.
That’s why a couple of years back I decided to remove Oj from Shopify’s monolith, and that’s when I discovered all the subtle differences
between Oj.mimic_JSON and the real json.
Ground Work
So my motivation was to hopefully make ruby/json perform about as well as oj on both real-world and micro-benchmark so that users
would no longer feel the need to monkey patch json for speed reasons. If they still feel like they need one of the more advanced oj APIs
that’s fine, but Oj.mimic_JSON should no longer feel appealing.
So the very first step was to setup a suite of benchmarks, comprising both micro-benchmarks and more meaty, real-world benchmarks. Thankfully, John Hawthorn’s rapidjson-ruby gem had such a benchmark suite, which I stole as a basis with some minor additions.
With that, all I needed was a decent C profiler. There are several options, but my favorite is samply, which has the nice property of outputting Firefox Profiler compatible reports that are easy to share.
Avoid Redundant Checks
I then started profiling the JSON.dump benchmark with the twitter.json payload:
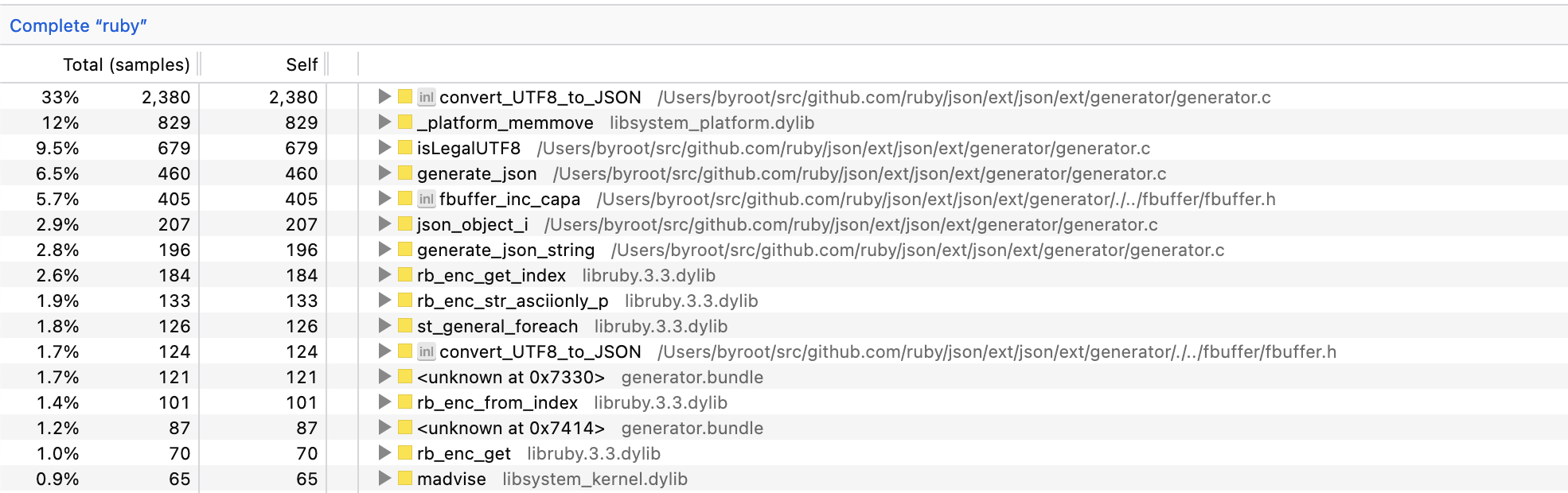
You need to know Ruby internals a bit to understand it all, but almost immediately something that surprised me was 9% of the time
spent in JSON’s own isLegalUTF8, and also 1.9% in rb_enc_str_asciionly_p, which is the C API version of String#ascii_only?.
The reason this is surprising is that Ruby string have some internal property called a coderange. For most string operations, Ruby does need to
know if it’s properly encoded, and for some operations, it can take shortcuts if the string only contains ASCII.
Since scanning a string to validate its encoding is somewhat costly, it keeps that property around so a string is only scanned once as long as it’s not mutated.
A coderange can be one of 4 values:
ENC_CODERANGE_UNKNOWN: the string wasn’t scanned yet.ENC_CODERANGE_VALID: the string encoding is valid.ENC_CODERANGE_7BIT: the string encoding is valid and only contains ASCII characters.ENC_CODERANGE_INVALID: the string encoding is invalid.
And some functions like rb_enc_str_asciionly_p are called, what they do is that if the coderange is unknown, they scan the string to compute it.
After that, it’s a very cheap integer comparison against ENC_CODERANGE_7BIT.
So convert_UTF8_to_JSON_ASCII had this weird thing where it would call rb_enc_str_asciionly_p at the very beginning, but then later it would
manually scan the string to see if it contains valid UTF-8, doing redundant work already performed by rb_enc_str_asciionly_p.
All this UTF-8 scanning could simply be replaced by a comparison of the string already computed coderange:
int ascii_only = rb_enc_str_asciionly_p(string);
if (!ascii_only) {
if (RB_ENCODING_GET_INLINED(string) != rb_utf8_encindex() ||
RB_ENC_CODERANGE(string) != RUBY_ENC_CODERANGE_VALID) {
rb_raise(rb_path2class("JSON::GeneratorError"),
"source sequence is illegal/malformed utf-8");
}
}Since C extensions code can be a bit cryptic when you’re not familiar with it, the Ruby version of that is simply:
unless string.ascii_only?
if string.encoding != Encoding::UTF_8 || !string.valid_encoding?
raise JSON::GeneratorError, "source sequence is illegal/malformed utf-8"
end
endHere both #ascii_only? and #valid_encoding? rely on the cached coderange, so the string would be scanned at most once, while previously
it could be scanned twice.
Unfortunately, that optimization didn’t perform as well as I initially expected:
== Encoding twitter.json (466906 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 105.000 i/100ms
Calculating -------------------------------------
after 1.113k (± 0.8%) i/s (898.26 μs/i) - 5.670k in 5.093474s
Comparison:
before: 1077.3 i/s
after: 1113.3 i/s - 1.03x faster
Given that isLegalUTF8 was reported as being 9% of the overall runtime, you’d expect that skipping it would speed up the code by 9%,
but it’s not that simple. A large part of the time that used to be spent in isLegalUTF8 instead went to convert_UTF8_to_JSON. While I’m not 100% sure,
the likely reason is that the larger part of these 9% was spent loading the strings content from RAM into the CPU cache, and not processing it.
Since we still go over these bytes later on, they still do the actually costly part of fetching the memory.
Still, a 3% improvement was nice to see.
Check the Cheaper, More Likely Condition First
In parallel to the previous patch, another function I looked at was fbuffer_inc_capa, reported as 5.7% of total runtime.
Looking at the profiler heat map of that function, I noticed that most of the time is spent checking if the buffer was already allocated or not:
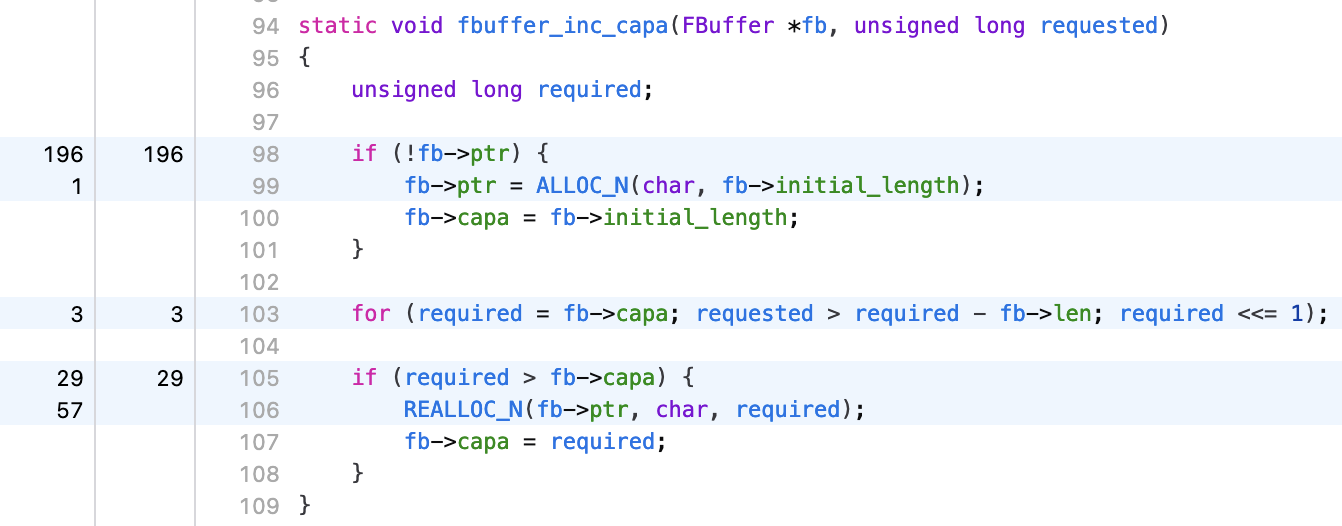
But this function is called every time we’re trying to write anything to the buffer and after the first call, the buffer is always already allocated. So that’s a lot of wasted effort for a condition that doesn’t match 99% of the time.
Also, that condition is a bit redundant with the if (required > fb->capa) one, as if the buffer wasn’t allocated yet, fb->capa would be 0,
hence, there’s no point checking it first, we should check it after we establish that the buffer capacity needs to be increased.
Another thing to know about modern CPUs is that they’re “superscalar”, meaning they don’t actually perform instruction one by one, but concurrently, and when faced with a branch, they take an educated guess at which branch is more likely to be taken and start executing that one immediately.
Based on that, it would be advantageous to instruct the CPU that both the if (required > fb->capa) and the if (!fb->ptr) conditions are very
unlikely to match.
To do that, compilers have various constructs, but Ruby helpfully exposes a macro to support most compilers with the same syntax: RB_LIKELY and RB_UNLIKELY.
Combining all these, led me to rewrite that function as:
static inline void fbuffer_inc_capa(FBuffer *fb, unsigned long requested)
{
if (RB_UNLIKELY(requested > fb->capa - fb->len)) {
unsigned long required;
if (RB_UNLIKELY(!fb->ptr)) {
fb->ptr = ALLOC_N(char, fb->initial_length);
fb->capa = fb->initial_length;
}
for (required = fb->capa; requested > required - fb->len; required <<= 1);
if (required > fb->capa) {
REALLOC_N(fb->ptr, char, required);
fb->capa = required;
}
}
}With this new version, we first check for the most common case, which is when the buffer still has enough capacity, and we instruct the CPU that
it’s the most likely case. Also, the function is now marked as inline, to suggest to the compiler not to go through the cost of calling a function,
but to directly embed that logic in the caller. As a result, the vast majority of the time, the work necessary to ensure the buffer is large enough
is just a subtraction and a comparison, very much negligible on modern CPUs.
That change led to a 15% improvement.
== Encoding twitter.json (466906 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 121.000 i/100ms
Calculating -------------------------------------
after 1.225k (± 0.8%) i/s (816.54 μs/i) - 6.171k in 5.039186s
Comparison:
before: 1068.6 i/s
after: 1224.7 i/s - 1.15x faster
And if you think about it, it’s not that specific to C, you can apply the same general idea to Ruby code as well, by checking the cheapest and most likely conditions first.
Reducing Setup Cost
I also wasn’t alone in optimizing ruby/json, Yusuke Endoh aka Mame, a fellow Ruby committer also had an old open PR with
numerous optimizations. Many of these reduced the “setup” cost of generating JSON.
What I describe as setup cost, is all the busy work that needs to be done before you can get to do the work you want. In the case of JSON generation, it includes parsing the arguments, allocating the generator and associated structures, etc.
ruby/json setup cost was quite higher than the alternative, and it’s because of this it always looked bad on micro-benchmarks.
For instance JSON.generate has 3 options to allow to generate “pretty” JSON:
>> puts JSON.generate({foo: [1]}, array_nl: "\n", object_nl: "\n", indent: " ", space: " ")
{
"foo": [
1
]
}Before Mame’s changes, the provided strings would be used to precompute delimiters into dedicated buffers. A Ruby equivalent of the code would be:
def initialize(opts)
@array_delim = ",#{opts[:array_nl]}"
@object_delim = ",#{opts[:object_nl]}"
@object_delim2 = ":#{opts[:space]}"
endThe idea makes sense, you precompute some string segments so you can append a single longer segment instead of two smaller ones.
But in practice this ended up much slower, both because this precompute doesn’t really save much work, but also because most of the time these options aren’t used. So by essentially reverting this optimization, Mame reduced the setup cost significantly. On larger benchmarks, the difference isn’t big, but on micro-benchmarks, it’s quite massive:
== Encoding small hash (65 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 308.914k i/100ms
Calculating -------------------------------------
after 3.199M (± 1.1%) i/s (312.57 ns/i) - 16.064M in 5.021536s
Comparison:
before: 2112189.3 i/s
after: 3199311.0 i/s - 1.51x faster
Avoid Chasing Pointers
Another notable optimization in Mame’s pull request was to eliminate one call to rb_enc_get.
In many places, JSON needs to check that strings are UTF-8 compatible, and was doing it this way:
static int enc_utf8_compatible_p(rb_encoding *enc)
{
if (enc == rb_usascii_encoding()) return 1;
if (enc == rb_utf8_encoding()) return 1;
return 0;
}
// ...
if (!enc_utf8_compatible_p(rb_enc_get(obj))) {
// try to convert the string
}At first sight, this might seem quite straightforward. But rb_enc_get is quite slow. Here’s most of its implementation:
int
rb_enc_get_index(VALUE obj)
{
int i = -1;
VALUE tmp;
if (SPECIAL_CONST_P(obj)) {
if (!SYMBOL_P(obj)) return -1;
obj = rb_sym2str(obj);
}
switch (BUILTIN_TYPE(obj)) {
case T_STRING:
case T_SYMBOL:
case T_REGEXP:
i = enc_get_index_str(obj);
break;
case T_FILE:
tmp = rb_funcallv(obj, rb_intern("internal_encoding"), 0, 0);
if (NIL_P(tmp)) {
tmp = rb_funcallv(obj, rb_intern("external_encoding"), 0, 0);
}
if (is_obj_encoding(tmp)) {
i = enc_check_encoding(tmp);
}
break;
case T_DATA:
if (is_data_encoding(obj)) {
i = enc_check_encoding(obj);
}
break;
default:
break;
}
return i;
}
rb_encoding*
rb_enc_get(VALUE obj)
{
return rb_enc_from_index(rb_enc_get_index(obj));
}As you can see, it’s a higher-level API implemented in a fairly defensive way, it performs a lot of type checks to ensure it won’t cause a crash and to be able to deal with different types of objects. All these conditionals don’t look like much, but as mentioned before, modern CPUs are very fast at computing things but pay a high price for conditionals unless they’re correctly predicted.
Then the thing to know is that conceptually, Ruby strings have a reference to their encoding, e.g.:
"Hello World".encoding # => Encoding::UTF_8So conceptually, they have a reference to another object, which naively should be a full-on 64-bit pointer. But since there’s only a (not so) small number of possible encodings,
instead of wasting a full 8 bytes to keep that reference, the Ruby VM instead stores a much smaller 7-bit number in a bitmap inside each String, which is called the encoding_index
or enc_idx for short.
That’s an offer you can use to then look up the actual encoding in a global array inside the virtual machine.
In low-level code that’s what we tend to call “pointer chasing” as in we have an address of memory, and go fetch its content from RAM.
If that RAM was recently loaded and is already in the CPU cache, it’s relatively fast, but if it isn’t, the CPU has to wait quite a long time for the data to be fetched.
If you are mostly working with higher-level languages, that probably doesn’t sound like much, but with low-level programming, fetching memory from RAM is a bit like performing a SQL query for a Rails application, it’s way slower than doing a computation on already fetched data, so similarly, that’s something you try hard not to do in hot spots.
In this case, there are several shortcuts json could take.
First json already knows it is dealing with a String, as such it doesn’t need to go through all the checks in rb_enc_get_index and can directly
use the lower level and much faster RB_ENCODING_GET.
Then, since all it cares about is whether the String is encoded in either ASCII or UTF-8, it doesn’t need the real rb_encoding * pointer, and
can directly check the returned index, skipping the need to load data from RAM.
So here’s how Mame rewrote that code:
static int enc_utf8_compatible_p(int enc_idx)
{
if (enc_idx == usascii_encindex) return 1;
if (enc_idx == utf8_encindex) return 1;
return 0;
}
// ...
if (!enc_utf8_compatible_p(RB_ENCODING_GET(obj))) {
// try to convert the string
}Notice how it is now comparing encoding indexes instead of encoding pointers.
That very small change improved the twitter.json benchmark by another 8%:
== Encoding twitter.json (466906 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 126.000 i/100ms
Calculating -------------------------------------
after 1.253k (± 1.5%) i/s (797.91 μs/i) - 6.300k in 5.028081s
Comparison:
before: 1159.6 i/s
after: 1253.3 i/s - 1.08x faster
Lookup Tables
Yet another patch in Mame’s PR was to use one of my favorite performance tricks, what’s called a “lookup table”.
Dumping a string into JSON can be quite costly because for each character there are multiple checks to do first to know if the character can simply be copied or if it needs to be escaped. The naive way looks like this (implemented in Ruby for better readability):
buffer = +""
string.each_char do |char|
if char.ord < 0x20 # ASCII control character
case char
when "\n"
buffer << "\\n"
when "\r"
buffer << "\\r"
when "\t"
buffer << "\\t"
when "\f"
buffer << "\\f"
when "\b"
buffer << "\\b"
else
buffer << "\u00#{char.ord}"
end
else
case char
when '"'
buffer << '\\"'
when '\\'
buffer << '\\\\'
else
buffer << char
end
end
endAs you can see, it’s a lot of conditional, even in the fast path, we need to check for c < 0x20 and then for " and \ characters.
The idea of lookup tables is that you precompute a static array with that algorithm so that instead of doing multiple comparisons per character, all you do is read a boolean at a dynamic offset. In Ruby that would look like this:
JSON_ESCAPE_TABLE = Array.new(256, false)
0x20.times do |i|
JSON_ESCAPE_TABLE[i] = true
end
JSON_ESCAPE_TABLE['"'] = true
JSON_ESCAPE_TABLE['\\'] = true
buffer = +""
string.each_char do |char|
if JSON_ESCAPE_TABLE[char]
# do the slow thing
else
buffer << char
end
endThis uses a bit more static memory, but that’s negligible and makes the loop much faster.
With this, and based on the assumption that most strings don’t contain any character that needs to be escaped, Mame added a precondition to first cheaply check if we’re on the fast path, and if we are, directly copy the entire string in the buffer all at once, so something like:
buffer = +""
if string.each_char.none? { |c| JSON_ESCAPE_TABLE[c] }
buffer << string
else
# do the slow char by char escaping
endYou can see Mame’s patch, it’s a bit more cryptic because in C, but you should be able to
see the same pattern as described here, and that alone made a massive 30% gain on the twitter.json benchmark:
== Encoding twitter.json (466906 bytes)
ruby 3.4.0rc1 (2024-12-12 master 29caae9991) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 164.000 i/100ms
Calculating -------------------------------------
after 1.630k (± 2.3%) i/s (613.43 μs/i) - 8.200k in 5.032935s
Comparison:
before: 1258.1 i/s
after: 1630.2 i/s - 1.30x faster
To Be Continued
I have way more optimizations than these ones to talk about, but I feel like it’s already a pretty packed blog post.
So I’ll stop here and work on some followup soon, hopefully I won’t lose my motivation to write :).
Edit: Looks like I didn’t, part two is here.