Optimizing Ruby's JSON, Part 7
In the previous post, we started covering some parser optimizations.
There’s just a handful more to cover until we reached what’s the state of the currently released version of ruby/json.
Batch APIs
But as always, let’s start with a flame graph of twitter.json, to see what was left to optimize:
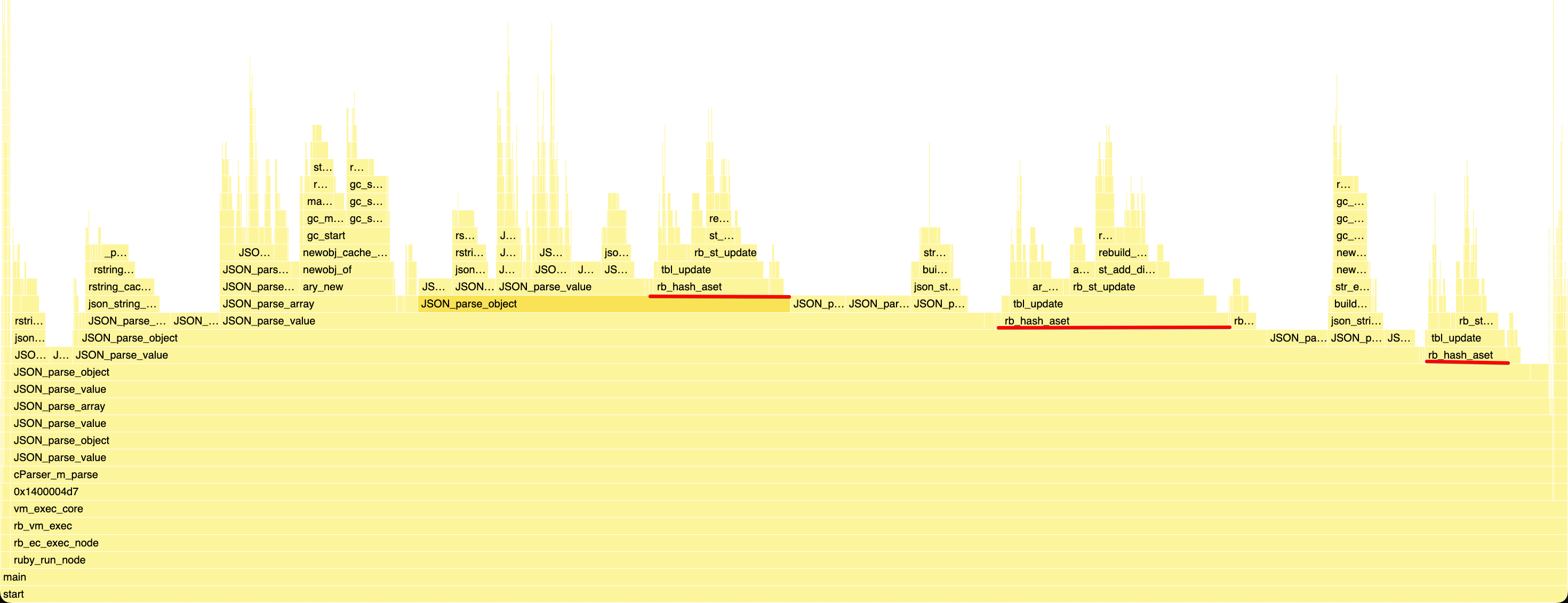
Something that was bothering me in that profile, was the whopping 26.6% of time spent in rb_hash_aset,
which is the C API for Hash#[]=.
It wasn’t really surprising to me though. I’m sure you’ve heard about some super fast JSON parsers like simdjson, rapidJSON etc,
Some of you may have wondered why I didn’t just do a binding of one of these to make ruby/json faster.
Aside from many technical and legal restrictions, a big reason is that actually parsing JSON isn’t that much of a bottleneck,
even the fairly naive Ragel parser in ruby/json isn’t that slow (It could be way better though, but more on that later).
No, the really expansive part is building the Ruby objects tree, as evidenced by the time spent in rb_hash_aset on that
flame graph, but also in rb_ary_push on benchmarks that use a lot of arrays. So a custom parser can potentially end up faster
overall by being better tailored to make efficient use of Ruby APIs, such as how we do unescaping inside Ruby strings to avoid
extra copies and cache string keys.
But let’s focus on that part of the flame graph to see why rb_hash_aset is slow, and what we could do about it:

I want to draw your attention to two things in this flame graph.
The first is ar_force_convert_table on the left. You may have noticed that many functions in the graphs are prefixed with
st_ or rb_st and a few with ar_.
The st_ ones are referring to st.c, Ruby’s internal Hash Table implementation.
What the st name stands for however I don’t know. st.c is a relatively well-optimized hash table that evolved over the years,
which is to be expected given how much Ruby relies on hash tables, even a modest performance gain in that data structure can have a
big impact overall. You can read its preamble if you want more details.
As for ar_, which I believe stands for “array”, refers to an optimization Ruby hashes do under the hood.
Hash tables are great, and offer a good access performance when the dataset is large, but when it’s very small they use quite a
lot of memory and aren’t really any better than a linear search. And Ruby code uses a lot of very small hash tables.
So Ruby hashes have an internal limit, RHASH_AR_TABLE_MAX_SIZE,
which on 64-bit platforms is 8. Any Ruby Hash that contains 8 or fewer entries is actually lying to you, and is just an array
in a trenchcoat. That’s what ar_table is, a simple array of key and value pairs being used as an associative array.
And yes, its algorithmic complexity is technically O(n), but with such a small n, it often is faster than doing all the hashing.
And if you add enough items in a Hash backed by an ar_table, it will be converted automatically to a st_table. That’s what
the ar_force_convert_table function does.
You can somewhat see this using one of my favorite APIs, ObjectSpace.dump:
>> require "objspace"
>> puts ObjectSpace.dump(8.times.to_h { |i| [i, i] })
{"address":"0xf3d8", "type":"HASH", "slot_size":160, "size":8, "memsize":160, ...}This tells us a Hash with 8 keys fits neatly in a 160B object slot. Each object reference is 8B, 2 references per entry,
16 * 8 => 128, so with a few extra metadata and perhaps a bit of wasted space, it checks out.
But if we do the same with a Hash with 9 items, the result is very different:
>> puts ObjectSpace.dump(9.times.to_h { |i| [i, i] })
{"address":"0x1230", "type":"HASH", "slot_size":160, "size":9, "memsize":544, ...}544B, that’s a big jump, but not so surprising. Hash tables almost by definition need to be somewhat large to not collide too much.
The other function on the flame graph I’d like to point out is rebuild_table_if_necessary, which stems from the same concern,
when you append to a Hash table, and it starts to get a bit too full, you have to increase its size, and contrary to an array,
it’s not just a matter of calling realloc, you have to essentially allocate a larger table, and then re-insert all the pairs
which means hashing the keys again, and that’s costly.
The problem though, is that exactly what we’re doing. When we encounter the start of a JSON object ({), we allocate a Ruby
Hash with rb_hash_new, and then every time we’re done parsing a key-value pair, we call rb_hash_aset to append to the hash.
So if a JSON document contains an object with 30 keys, we first allocate an ar_table with a capacity of 8 pairs, get it rebuilt
as a st_table that can hold 16 entries, and finally a third time with 32 entries. Meaning we’re hashing every key 3 times,
and wasting time in malloc and free.
When parsing a format like msgpack, or Ruby’s Marshal, the byte that signals the start of a Hash is followed by the expected
size of the Hash, allowing you to pre-allocate it with the right size, which helps a lot.
But JSON doesn’t have that, we have no choice but to parse as we go, and we’ll only know how big the Hash is once we’re done
parsing it.
The problem is the same with large arrays, they start embedded, and then double in size every time they run out of space, it’s just not quite as bad because at least we don’t hash to re-hash the keys.
But looking at the flame graph above, we can see that all this resizing is a majority of the time spent in rb_hash_aset, and
rb_hash_aset over a quarter of the overall time, so there was really a big opportunity here.
If it’s a bad idea to directly append to a Hash before we know how large it will be, why don’t we just wait to be done parsing it before we build it? Basic.
But that means we need to store its content somewhere else in the meantime, and the ideal structure for that is a stack, which is just a fancy name for an array.
You can look at the full patch in C, but I’ll try to explain the key concept with some Ruby code here.
Before the parsing code was something like this:
def parse_object
hash = {}
until object_done?
key = parse_object_key
value = parse_json
hash[key] = value
end
hash
endWe simply parse until we find the object terminator, and until then we append to the Hash whenever we get a complete pair, and each parsing function simply returns the parsed object.
After the change it now looks more something like this:
def parse_object(stack)
previous_size = stack.size
until object_done?
stack << parse_object_key
stack << parse_json
end
hash = stack.pop(stack.size - previous_size).to_h
stack << hash
hash
endEvery parse function now receives an array to use as the parsing stack, whatever they parse, they push on the stack.
The parse_object function is no exception, it first records how large the stack is, then it parses keys and values
and push them both on the stack.
Once the end of the object is found, all the pairs are popped from the back of the stack, and a hash is immediately created with
the right size, ensuring each key is only hashed once.
In C, it looks like this:
long count = json->stack->head - stack_head;
VALUE hash;
#ifdef HAVE_RB_HASH_NEW_CAPA
hash = rb_hash_new_capa(count >> 1);
#else
hash = rb_hash_new();
#endif
rb_hash_bulk_insert(count, rvalue_stack_peek(json->stack, count), hash);
*result = hash;
rvalue_stack_pop(json->stack, count);You should be able to recognize the pattern, we create a hash of the right size using the rb_hash_new_capa API,
which unfortunately we have to test for its existence because unfortunately I only exposed it to C extensions a few years ago.
Then we insert all pairs at once with rb_hash_bulk_insert.
And that’s it, with just that change, the twitter.json benchmark was sped up by 22%:
== Parsing twitter.json (567916 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 90.000 i/100ms
Calculating -------------------------------------
after 897.170 (± 0.4%) i/s (1.11 ms/i) - 4.500k in 5.015857s
Comparison:
before: 737.1 i/s
after: 897.2 i/s - 1.22x faster
Avoid Double Scanning
After the value stack patch was so effective, json_string_unescape was back to being the biggest bottleneck at 22% of total runtime:
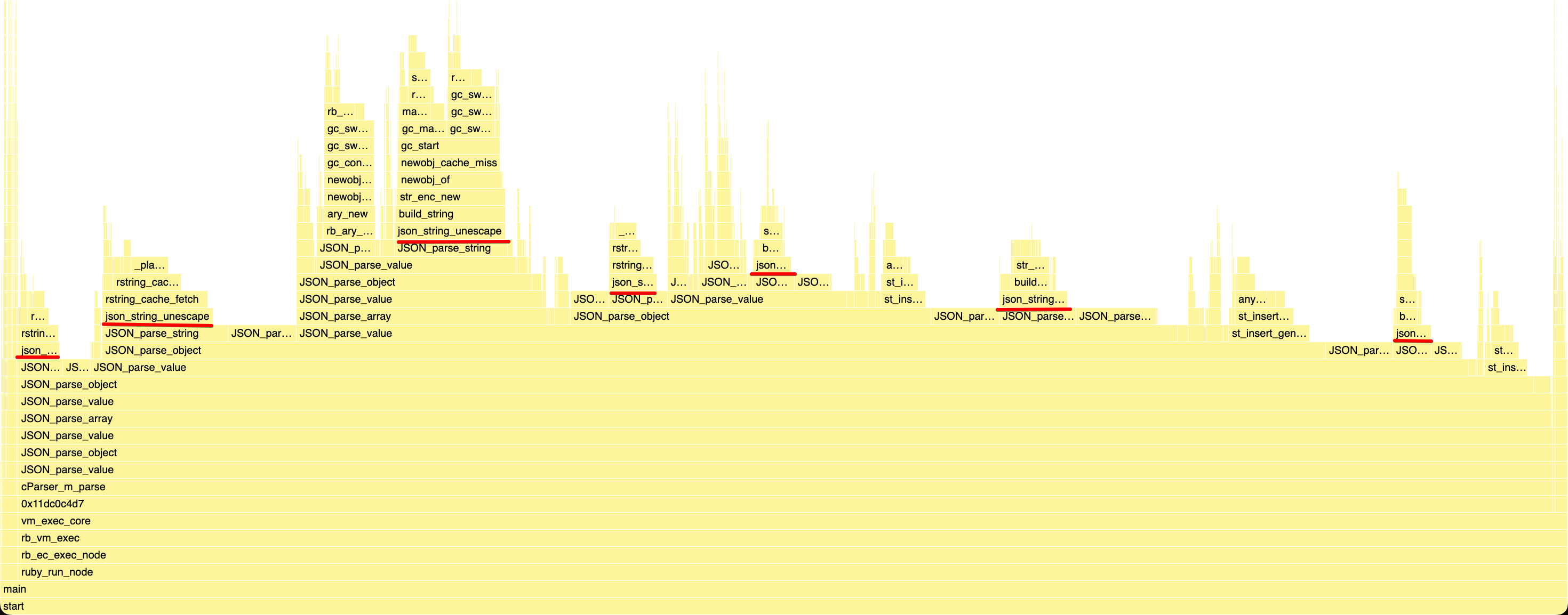
I had recently optimized it by optimistically assuming most strings don’t contain any escape character, but something still
bothered me. The Ragel parser calls our JSON_parse_string callback with both the start and end pointer of the string, to do
that it has to scan the string, so it’s a bit silly that the first thing we immediately do right after that is to scan it all over
again.
It would be way better if while it is looking for the end of the string, the Ragel parser would record if it had seen any backslash, and if not, we’d save on re-scanning it again.
Here’s how the JSON strings grammar was defined:
%%{
machine JSON_string;
include JSON_common;
write data;
action parse_string {
*result = json_string_unescape(json, json->memo + 1, p, json->parsing_name, json->parsing_name || json-> freeze, json->parsing_name && json->symbolize_names);
if (NIL_P(*result)) {
fhold;
fbreak;
} else {
fexec p + 1;
}
}
action exit { fhold; fbreak; }
main := '"' ((^([\"\\] | 0..0x1f) | '\\'[\"\\/bfnrt] | '\\u'[0-9a-fA-F]{4} | '\\'^([\"\\/bfnrtu]|0..0x1f))* %parse_string) '"' @exit;
}%%If you don’t understand it, don’t worry, me neither.
That’s where I kinda need to confess that I don’t have a proper computer science education, more some sort of very applied
software engineering curriculum, and not a particularly good one, so terms like “formal grammar” and parser generators like Ragel
et al kind of fly over my head, hence I’m kinda struggling to improve the core parsing parts. And I also can’t rely on
my usual tricks to work with things I don’t fully grasp because Ragel outputs absolutely disgusting code with lots of goto,
which makes it super hard to learn by experimentation.
Yet, even with my limited understanding, I can say something is really off here. We can see on the last line that we’re basically instructing Ragel about all the possible escape sequences inside a JSON string, which to me doesn’t make much sense. All we need the parser to do for us is to know enough to find the end of the string, tell us it ran into the end of the stream without finding it, or if it ran into an invalid character (e.g. a newline).
It absolutely doesn’t need to validate that \u is followed by 4 hexadecimal characters, we can do that during unescaping.
But anyway, this is for strings with escape sequences, and we don’t have that many of those, I had to figure out a way to have a fast path for simple strings, and after a few hours of struggling and begging some properly educated people for help I managed to get this:
%%{
machine JSON_string;
include JSON_common;
write data;
action parse_complex_string {
*result = json_string_unescape(json, json->memo + 1, p, json->parsing_name, json->parsing_name || json-> freeze, json->parsing_name && json->symbolize_names);
fexec p + 1;
fhold;
fbreak;
}
action parse_simple_string {
*result = json_string_fastpath(json, json->memo + 1, p, json->parsing_name, json->parsing_name || json-> freeze, json->parsing_name && json->symbolize_names);
fexec p + 1;
fhold;
fbreak;
}
double_quote = '"';
escape = '\\';
control = 0..0x1f;
simple = any - escape - double_quote - control;
main := double_quote (
(simple*)(
(double_quote) @parse_simple_string |
((^([\"\\] | control) | escape[\"\\/bfnrt] | '\\u'[0-9a-fA-F]{4} | escape^([\"\\/bfnrtu]|0..0x1f))* double_quote) @parse_complex_string
)
);
}%%The idea is simple, start by only looking for a double quote not preceded by any backslash, that’s the optimistic path, and if it
matches we enter parse_simple_string. If it doesn’t, we fall back to the previous pattern and end up in parse_complex_string.
The fast path is a much simpler function:
static VALUE json_string_fastpath(JSON_Parser *json, char *string, char *stringEnd, bool is_name, bool intern, bool symbolize)
{
size_t bufferSize = stringEnd - string;
if (is_name) {
VALUE cached_key;
if (RB_UNLIKELY(symbolize)) {
cached_key = rsymbol_cache_fetch(&json->name_cache, string, bufferSize);
} else {
cached_key = rstring_cache_fetch(&json->name_cache, string, bufferSize);
}
if (RB_LIKELY(cached_key)) {
return cached_key;
}
}
return build_string(string, stringEnd, intern, symbolize);
}Nothing particularly fancy. Unfortunately the impact on twitter.json wasn’t that big:
== Parsing twitter.json (567916 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 91.000 i/100ms
Calculating -------------------------------------
after 913.740 (± 0.3%) i/s (1.09 ms/i) - 4.641k in 5.079191s
Comparison:
before: 886.9 i/s
after: 913.7 i/s - 1.03x faster
I was a bit disappointed, but still, I progressed a bit in my understanding of Ragel and knew there was
lots of fishy things in ruby/json’s Ragel parser, so that would be useful.
Avoid Useless Copies
After that disappointment, I needed a bit of a break, so I went back to a function where I knew I could get better results on, integer parsing.
I didn’t have a micro-benchmark dedicated to integers, but the small array one would do:
benchmark_parsing "small nested array", JSON.dump([[1,2,3,4,5]]*10)So 10 arrays, with 5 integers each, quite simple.
And you know the drill, it started with some profiling.

As we mentioned in the previous part,
rb_cstr2inum, the API Ruby gives us to turn a C string into a Ruby Integer, isn’t very efficient.
First, because it expects a C string, it forces us to first copy the string into a buffer so we can append a NULL to it,
but also because it has to deal with quite a lot of cases we don’t care about, such as a variable base. For instance 0xff is a
valid number for rb_cstr2inum, but not for JSON. It also has to support arbitrary long integers, which slows it down, but the
overwhelming majority of the numbers we parse fit in 64 bits.
So we have an opportunity here for another fast path type of function, that would deal with the crux of integer parsing, and
for the rare and complex cases, continue to rely on rb_cstr2inum.
The implementation is very straightforward, you can see the full patch, but I’ll detail the key parts:
static inline VALUE fast_parse_integer(char *p, char *pe)
{
bool negative = false;
if (*p == '-') {
negative = true;
p++;
}
long long memo = 0;
while (p < pe) {
memo *= 10;
memo += *p - '0';
p++;
}
if (negative) {
memo = -memo;
}
return LL2NUM(memo);
}We start by checking if the number is negative, then convert ASCII characters into the corresponding integer one by one.
The limitation, however, is that this can only work for an integer that fits in a native integer type, as such we only enter this fast path if the number of digits is low enough:
#define MAX_FAST_INTEGER_SIZE 18
long len = p - json->memo;
if (RB_LIKELY(len < MAX_FAST_INTEGER_SIZE)) {
*result = fast_parse_integer(json->memo, p);
} else {
fbuffer_clear(&json->fbuffer);
fbuffer_append(&json->fbuffer, json->memo, len);
fbuffer_append_char(&json->fbuffer, '\0');
*result = rb_cstr2inum(FBUFFER_PTR(&json->fbuffer), 10);
}Why 18? Because regardless of the CPU architecture, in C a long long must support a maximum value of 9,223,372,036,854,775,807
and a minimum value of −9,223,372,036,854,775,808, in other words, it’s always a 64-bit integer.
That’s 19 digits, but there are some 19-digit numbers that don’t fit in a long long, so 18.
It would be possible to handle slightly bigger numbers by using an unsigned long long, but I didn’t think it was worth it.
As for the impact on the micro-benchmark, it was pretty good:
== Parsing small nested array (121 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 124.666k i/100ms
Calculating -------------------------------------
after 1.258M (± 2.3%) i/s (794.63 ns/i) - 6.358M in 5.055135s
Comparison:
before: 816626.3 i/s
after: 1258454.3 i/s - 1.54x faster
But that’s a micro-benchmark of course, here’s the effect on more realistic ones:
== Parsing twitter.json (567916 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 92.000 i/100ms
Calculating -------------------------------------
after 939.320 (± 1.0%) i/s (1.06 ms/i) - 4.784k in 5.093485s
Comparison:
before: 875.5 i/s
after: 939.3 i/s - 1.07x faster
== Parsing citm_catalog.json (1727030 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 43.000 i/100ms
Calculating -------------------------------------
after 430.366 (± 0.9%) i/s (2.32 ms/i) - 2.193k in 5.096015s
Comparison:
before: 388.8 i/s
after: 430.4 i/s - 1.11x faster
Avoid Duplicated Work
The final parser optimization that shipped with json 2.9.0, was submitted by Aaron Patterson.
I’m not too sure how he got to work on it, perhaps he was attracted by the smell of blood when he saw me cursing
against Ragel in our company Slack, who knows?
The key element of Aaron’s patch is that he changed this:
np = JSON_parse_float(json, fpc, pe, result);
if (np != NULL) {
fexec np;
}
np = JSON_parse_integer(json, fpc, pe, result);Into this:
np = JSON_parse_number(json, fpc, pe, result);If it’s not yet obvious, the previous version of the parser would first try to parse a float, and if it failed to do so,
would try to parse an integer. This is quite wasteful, because all floats start with an integer, so whenever the next value to
parse was an integer, it would first be fully scanned by JSON_parse_float to figure out it’s not an integer, and then the parser
would backtrack and scan the same bytes again in JSON_parse_integer.
You can look at the full patch, which also contains some changes to the grammar and state machine to make the above change possible, but that really is the core of it.
And you might think it’s indeed more efficient, but probably not that big of a deal in the grand scheme of things, but actually
it did speedup twitter.json and citm_catalog.json by a nice 5%:
== Parsing twitter.json (567916 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 95.000 i/100ms
Calculating -------------------------------------
after 947.551 (± 0.9%) i/s (1.06 ms/i) - 4.750k in 5.013354s
Comparison:
before: 904.4 i/s
after: 947.6 i/s - 1.05x faster
== Parsing citm_catalog.json (1727030 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
after 45.000 i/100ms
Calculating -------------------------------------
after 458.244 (± 0.2%) i/s (2.18 ms/i) - 2.295k in 5.008296s
Comparison:
before: 432.7 i/s
after: 458.2 i/s - 1.06x faster
Fin?
And that’s it, that was the final optimization performed before I released json 2.9.0, so I will conclude this series.
If you wonder how fast it now is, here’s a final twitter.json benchmark against the competition:
== Parsing twitter.json (567916 bytes)
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +YJIT +PRISM [arm64-darwin23]
Warming up --------------------------------------
json 93.000 i/100ms
oj 66.000 i/100ms
Oj::Parser 80.000 i/100ms
rapidjson 58.000 i/100ms
Calculating -------------------------------------
json 928.472 (± 0.3%) i/s (1.08 ms/i) - 4.650k in 5.008282s
oj 666.198 (± 0.8%) i/s (1.50 ms/i) - 3.366k in 5.052899s
Oj::Parser 803.031 (± 0.2%) i/s (1.25 ms/i) - 4.080k in 5.080788s
rapidjson 584.869 (± 0.2%) i/s (1.71 ms/i) - 2.958k in 5.057565s
Comparison:
json: 928.5 i/s
Oj::Parser: 803.0 i/s - 1.16x slower
oj: 666.2 i/s - 1.39x slower
rapidjson: 584.9 i/s - 1.59x slower
That isn’t to say I’m done optimizing, I have quite a few ideas for the future, but I wanted to stabilize the gem prior to the release of Ruby 3.4.0, and I feel it is now fast enough that there’s no urgency.
But to give you an idea of what may happen in the future, I’d like to drop Ragel and replace it with a simpler recursive descent parser. The existing one could certainly be improved, but I find it much harder to work with generated parsers than to write them manually.
I’m also currently pairing with Étienne Barrié on a better API for both the parser and the encoder which would allow to reduce the setup cost even further, stop relying as much on global state, and would generally be more ergonomic.
I hope you enjoyed this blog series, I’ll try to continue writing, next, I’d like to share some thoughts on Pitchfork, but I may need to set the stage for it with other posts to explain some key concepts.